Ressourcenmanagement
In SYSTRAN Translate können Sie eine Vielzahl von linguistischen Ressourcen über das Menü Resources verwalten.
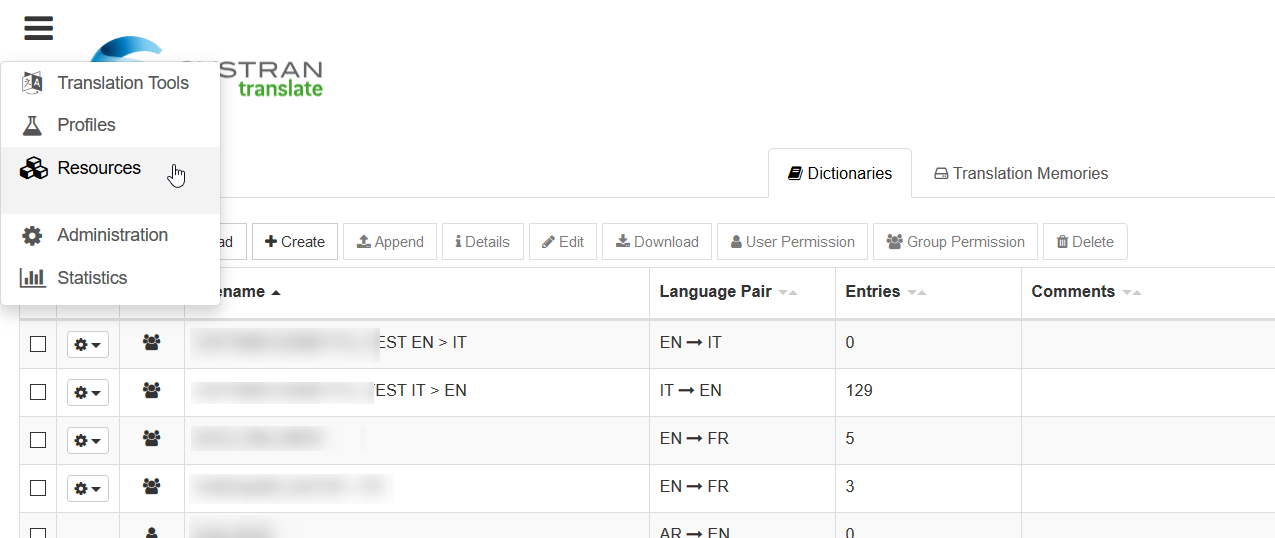
Auf diese Weise können Benutzer leistungsstarke, an ihre Übersetzungsanforderungen angepasste linguistische Ressourcen implementieren. Benutzer können einem Profil Translation Memorys und zusätzliche Wörterbücher wie Domänenwörterbücher hinzufügen, um die Übersetzungen zu verbessern.
Sobald Ressourcen fertig gestellt sind, können sie über die Profilseite zu einem Profil hinzugefügt werden.
Bemerkung
UD und TM können nicht mit Pivot-Profilen verwendet werden.
Berechtigungen
Es ist möglich, die folgenden Elemente mit bestimmten Benutzern oder Gruppen zu teilen:
Eigene Wörterbücher
Translation Memorys
Klicken Sie für jedes Element auf die Schaltfläche „Benutzerberechtigung“ oder „Gruppenberechtigung“, um das Popup-Fenster mit der Berechtigungszuweisung zu öffnen:
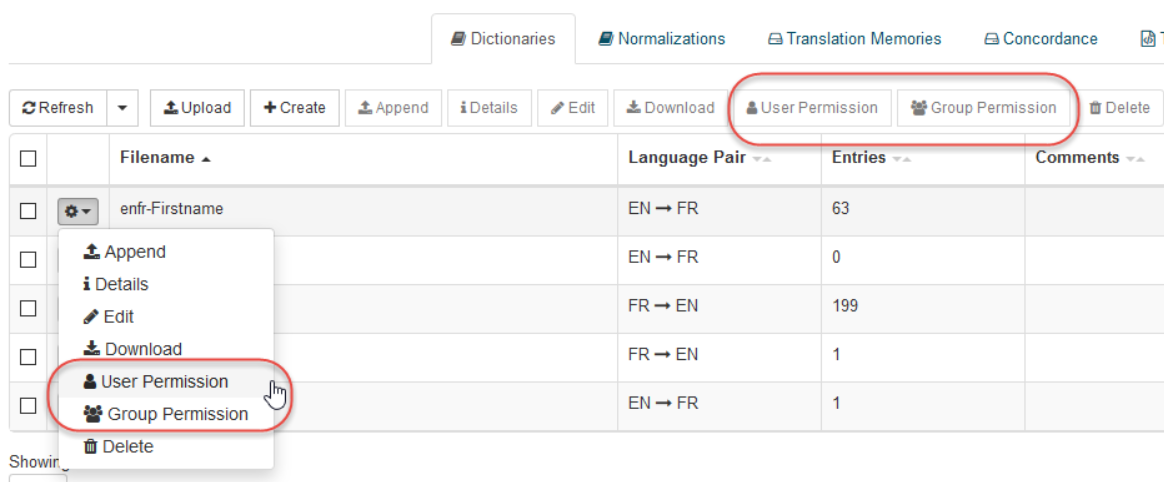
Nachdem Sie das Popup-Fenster mit den Berechtigungen geöffnet haben, können Sie Berechtigungen auf der Benutzer-/Gruppenebene zuweisen, indem Sie den Benutzer- oder Gruppennamen auswählen. Dann:
Wählen Sie die entsprechende Berechtigung in der Symbolleiste oder im Dropdown-Menü aus, die bzw. das dem Benutzer/der Gruppe zugeordnet ist (weitere Informationen finden Sie unten)
Klicken Sie auf „Speichern“ für den angegebenen Benutzer
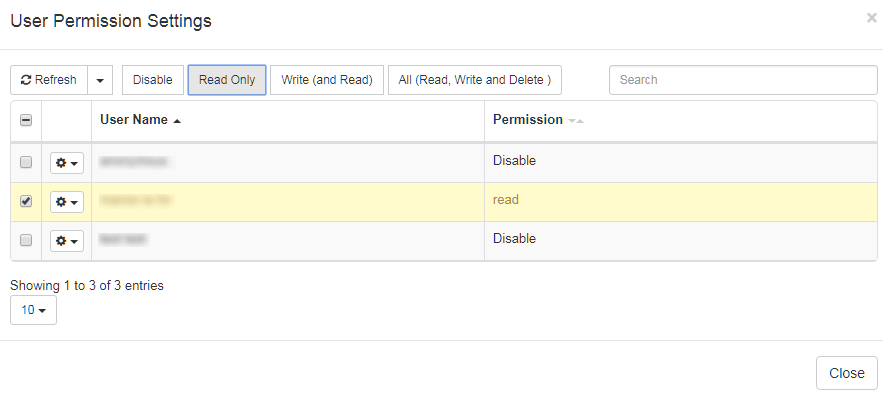
Benutzern oder Gruppen können die folgenden Berechtigungen gewährt werden:
Deaktivieren: (standardmäßig) das Element ist nicht sichtbar Schreibgeschützt:
Das Element kann in einem schreibgeschützten Modus aus der Liste eingegeben werden (wenn der Benutzer über die Berechtigung zum Zugriff auf die Ressourcenliste verfügt, z. B. das Translation Memory-Menü)
Das Element kann vom Benutzer in einem Profil ausgewählt werden (wenn der Benutzer über die Berechtigung zum Erstellen von Profilen verfügt)
Das Element wird in den Suchergebnissen der Tools für die „Textübersetzung“ enthalten sein (d. h. Elemente aus dem Wörterbuch oder aus dem Translation Memory können im Feld „Wörterbuch-Suche“ oder in den Suchergebnissen des Translation Memory angezeigt werden)
Schreiben‘ (und Lesen): dieselben Rechte wie oben, plus
Der Benutzer kann die Ressource eingeben und ändern
Alle (Lesen, Schreiben und Löschen): dieselben Rechte wie oben, plus
Der Benutzer kann das Element auch löschen und die Berechtigungen des Elements für andere Benutzer festlegen
Ein Berechtigungsmechanismus wird auch für Profile und aktive Profile in den kommenden Versionen implementiert.
Wörterbücher
Eigene Wörterbücher können einem Profil zugewiesen werden, um die Qualität der Übersetzungen zu verbessern. Die Qualität von Übersetzungssoftware hängt direkt vom Grad des „Verständnisses“ des Systems ab. Um ein gutes „Verständnis“ zu erlangen, muss das System nicht nur eine korrekte syntaktische Analyse des Textes, sondern auch eine korrekte semantische Analyse erhalten. Dies liegt daran, dass einige Wörter je nach semantischem Kontext, in dem sie verwendet werden, unterschiedliche Bedeutungen und ein unterschiedliches syntaktisches Verhalten haben. Eigene Wörterbucheinträge setzen die über eine Million eingebauten Einträge in den Hauptwörterbüchern von SYSTRAN während des Übersetzungsprozesses außer Kraft.
Wörterbücher aktualisieren
Von der Liste Wörterbücher können Sie die folgenden Aktionen für Wörterbücher ausführen:
Anhängen → Einträge durch Hochladen der Datei hinzufügen; weitere Details unten
Bearbeiten → Einträge hinzufügen und bearbeiten; weitere Details unten
Details → Ändern Sie die Eigenschaften des Wörterbuchs (Name, Ausgangs- und Zielsprache), und fügen Sie Kommentare hinzu oder bearbeiten Sie diese.
Download → Wörterbuch herunterladen
Wörterbücher hochladen
Um Einträge in das Wörterbuch hochzuladen, wählen Sie ein Wörterbuch aus, klicken Sie auf die Schaltfläche ‚Anhängen‘ und laden Sie ein Wörterbuch im Binärformat (.dct), Microsoft Excel (.xls) oder Nur-Text (.txt) hoch.
Bemerkung
Wir empfehlen, UD hochzuladen, die 200000 Segmente nicht überschreitet.
Wörterbücher, die mit einer Tabellenkalkulationsanwendung wie Microsoft Excel oder einem allgemeinen Texteditor erstellt wurden, müssen sorgfältig formatiert werden, bevor sie importiert werden können. Unten finden Sie eine detaillierte Beschreibung des Formats, das für den Import von Wörterbüchern erforderlich ist.
Microsoft Excel-Dateien
Um mit Microsoft Excel erstellte Wörterbücher zu importieren, müssen die Dateien aus einem Arbeitsblatt für eine Übersetzung bestehen, zum Beispiel aus dem Englischen ins Französische. Wie bei formatierten Textdateien müssen die Spaltenüberschriften der Microsoft Excel-Datei für die Sprachen und Informationsspalten für die UD unter Beachtung der 2-Buchstaben-ISO-639-Codesprache in Großbuchstaben eingegeben werden.
Formatierte Textdateien
Formatierte Textdateien, die in SYSTRAN Translate importiert werden können, enthalten die Kopfzeile des Dokuments und den Inhalt des Wörterbuchs. Die Überschrift des Wörterbuchs ist eine Abfolge von Zeilen, die mit dem Zeichen „#“ beginnen und ein Überschriftenfeld gefolgt von seinem Wert enthalten. Der Inhalt des Wörterbuchs ist eine Abfolge von Zeilen, wobei jede Zeile einen Wörterbucheintrag darstellt, dessen Felder durch Tabstoppzeichen getrennt sind. Die Feldtypen werden in der Kopfzeile definiert. Es ist wichtig, dass jede Zeile die gleiche Anzahl von Feldern enthält, auch wenn sie leer sind.
Erforderliche und optionale Felder zum Hochladen von Dateien auf SYSTRAN Translate:
Kopfzeile |
Beschreibung der Eingabe |
|---|---|
#COVERED DOMÄNEN= |
Optionale Überschrift: listet alle Domänen im Wörterbuch auf
Hinweis: gilt nicht für NMT
|
#ENCODING= |
Erforderlich: definiert die Kodierung der Datei. UTF-8-Kodierung wird empfohlen |
#GENERAL WÖRTERBUCHDOMÄNEN= |
Optionale Überschrift: listet die dem Wörterbuch zugeordneten Systemdomänen auf
Hinweis: gilt nicht für NMT
|
#SUMMARY= |
Erforderlich: der Name der UD-Datei |
#MULTI/TM/NORM/DNT #<Sprachen><Informationsspalten>= |
Erforderlich: Diese beiden Zeilen sind das Ende des Kopfzeilenabschnitts. #MULTI definiert, dass das Wörterbuch ein Benutzerwörterbuch ist #TM definiert, dass das Wörterbuch ein Translation Memory ist #NORM definiert, dass das Wörterbuch ein Normalisierungswörterbuch ist #DNT wird verwendet, um in einem Benutzerwörterbuch mehrsprachige Einträge von DNT-Einträgen zu trennen In der zweiten Zeile wird die Liste der Spalten im Inhaltsabschnitt beschrieben. Es ist eine Liste von Codes, die durch Tabulatorzeichen getrennt sind, wie in der folgenden Tabelle beschrieben |
Beschreibung der verschiedenen Codes zur Definition der Inhaltsfelder:
Code |
Beschreibung |
|---|---|
XX |
Dabei ist XX ein 2-stelliger ISO 639-Code in Großbuchstaben. Dies stellt eine Sprache dar (siehe Anhang B. Sprachpaare und ISO 639)
Codes).Die Ausgangssprache ist immer die erste Spalte, wobei die Zielsprachen die folgenden Spalten sind
|
XX_NR |
Nur für Normalisierungswörterbücher. XX entspricht dem ISO-639-Code für die Ausgangssprache. Diese Spalten repräsentieren
Normalisierte Spalten
|
UPOS |
Benutzerteil der Sprache. Akzeptiert POS: Akronym, Adjektiv, Adverb, Konjunktion, Substantiv, Präposition, Eigenname, Regel, Verb (in Kleinbuchstaben geschrieben).
Sie entsprechen dem POS in der Benutzeroberfläche, mit Ausnahme von Expression.
|
STICHWORT_XX |
Diese Spalte wird beim Exportieren erstellt. Er enthält das Stichwort des zugehörigen XX-Felds.
Beim Import wird diese Spalte ignoriert
|
PRIORITÄT |
Prioritätsspalte
Hinweis: gilt nicht für NMT
|
DOMÄNEN |
Domänen-Spalte. Domänen sind durch Kommas getrennt
Hinweis: gilt nicht für NMT
|
HÄUFIGKEIT |
Frequenzspalte |
BEISPIEL |
Beispielspalte |
Beispielformatierte Textdatei:
Die folgende Beispieltextdatei wurde für den Import als Benutzerwörterbuch bei SYSTRAN Translate formatiert. Beachten Sie, dass <TAB> das Tabulatorzeichen angibt.
#ENCODING=UTF-8
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#COVERED DOMAINS=Computers/Data Processing,Perso
#GENERAL DICTIONARY DOMAINS=Computers/Data Processing
#PRIORITY=1
#SUMMARY=Demo Computer
#MULTI
#EN<TAB>FR<TAB>NOTE<TAB>DOMAINS<TAB>PRIORITY<TAB>UPOS
white cycle<TAB>cycle d'écriture<TAB>Note<TAB>1<TAB>noun
write enable<TAB>validation écriture<TAB><TAB><TAB>noun
#DNT
#EN<TAB>NOTE<TAB>DOMAINS
Print 2000<TAB>It is a DNT<TAB>Perso
Die folgende Beispieltextdatei wurde für den Import in SDM als Translation Memory formatiert.
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#ENCODING=UTF-8
#SUMMARY=Demo
#TM
#EN<TAB>FR<TAB>DE
My name is Smith<TAB>Mon nom est Smith<TAB>Mein Name ist Smith
So verwenden Sie ein Benutzerwörterbuch mit einem Profil:
Klicken Sie auf Profile
Profile auswählen
Erweitern Sie die Profiloptionen
Wählen Sie unter Ressourcen das gewünschte Wörterbuch aus
Klicken Sie auf Absenden
Einträge importierter Wörterbücher können dann direkt auf dem Server geändert werden, indem Sie auf Bearbeiten klicken. Details zur Verwendung dieses Tools finden Sie weiter unten.
Bearbeiten von Wörterbüchern: Navigationstabelle
Klicken Sie auf Bearbeiten, um auf den Wörterbuch-Editor zuzugreifen.
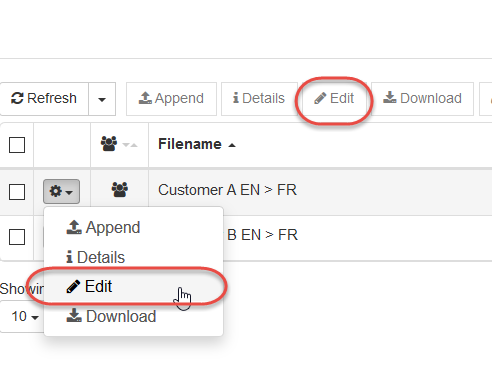
Dies öffnet eine neue Seite, die das Wörterbuch in Tabellenformat anzeigt, sodass Einträge angesehen, geändert, hinzugefügt oder entfernt werden können. Sie können Wörterbucheinträge filtern, indem Sie sie alphabetisch nach Spaltenüberschriften sortieren (Quelle, POS, Ziel, Priorität, Kommentare, Zuverlässigkeit). Zusätzliche Filterung kann durch Eingabe eines Schlüsselworts in das Suchfeld unter der Spaltenüberschrift erfolgen.
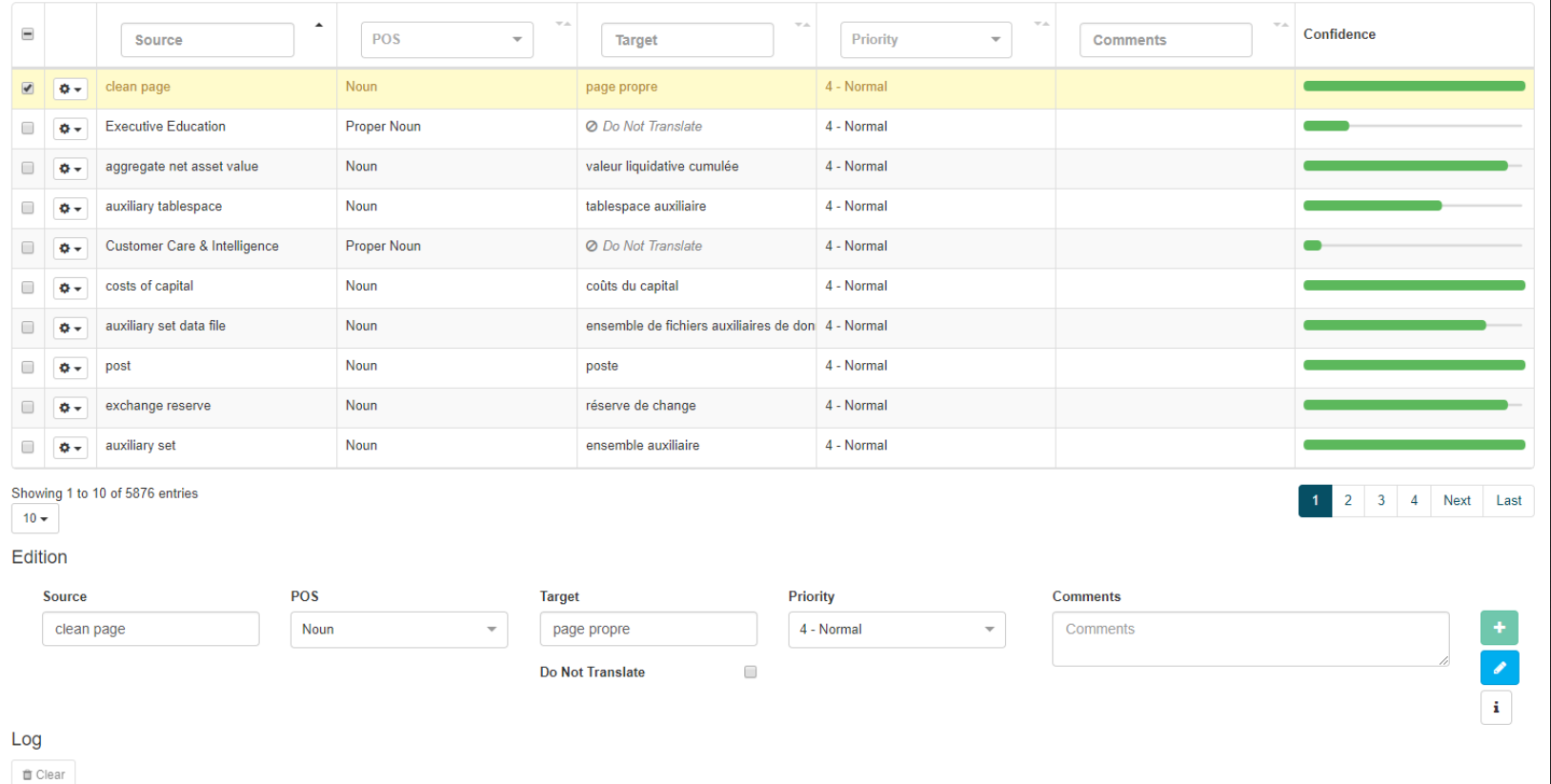
Auf dieser Seite können Sie die folgenden Informationen zu jedem Wörterbucheintrag anzeigen:
Quelle
Jeder einzelne oder mehrere Wörter umfassende Eintrag des Wörterbuchs wird zeilenweise unter dieser Spalte angezeigt. Klicken Sie auf das Symbol Inflections, um die Biegeinformationen des Eintrags abzurufen
POS
Der Teil des Quelleintrags. Die folgende Tabelle beschreibt die möglichen Wortarten:
POS |
Beschreibung |
Beispiele |
|---|---|---|
Akronym |
In der SYSTRAN-Terminologie ein Wort, das aus den Anfangsbuchstaben anderer Wörter oder aus Teilen einer Reihe von Wörtern gebildet wird |
|
adjektivisch |
Ein Wort, das zur Änderung von Substantiven und Pronomen verwendet wird. Enthält Einträge, die Mehrwortsequenzen enthalten, die als Block zusammengehalten und nicht flektiert werden sollen (in Anführungszeichen) |
|
Adverb |
Ein Wort, das Verben, Klauseln und Adjektive verändert. Kann für Mehrwortsequenzen verwendet werden, die als Block zusammengehalten und nicht flektiert werden sollen (in Anführungszeichen) |
|
Konjunktion |
Wörter, die als Verbinder verwendet werden. Hinweis: Wir raten dringend davon ab, diesen POS zu verwenden |
|
Ausdruck |
In der SYSTRAN-Terminologie eine Nominalphrase, die aus mehr als einem Substantiv oder einer beliebigen Kombination aus Substantiven und Adjektiven besteht, wobei das Stichwort ein Substantiv ist. Vollständige Sätze oder Phrasen, die Verben enthalten, sind ungültig |
|
Substantiv |
Ein Wort, das zum Benennen einer Person, eines Ortes, einer Sache, einer Qualität oder einer Aktion verwendet wird.Verwenden Sie Kleinbuchstaben, wenn Sie alle Groß- und Kleinbuchstaben (Groß- und Kleinbuchstaben) übereinstimmen möchten, und verwenden Sie doppelte Anführungszeichen, um die Wörter vor einer Flexion zu schützen |
|
Präposition |
Ein Wort, das vor einem Substantiv oder einer Nominalphrase platziert wird und die Beziehung dieses Substantivs oder der Nominalphrase zu einem Verb, einem Adjektiv oder einem anderen Substantiv oder einer anderen Nominalphrase angibt Hinweis: Wir raten dringend davon ab, diesen POS zu verwenden |
|
Eigenname |
Ein Substantiv, das zur Klasse der Wörter gehört, die für Personen, Unternehmen, Standorte usw. verwendet werden. Der Eintrag wird nicht beeinflusst. Verwenden Sie Kleinbuchstaben, wenn alle Groß- und Kleinbuchstaben übereinstimmen sollen |
|
Herrschaft |
Wird in Normalisierungswörterbüchern verwendet, um den Eintrag und seine gebeugten Formen einander zuzuordnen. Wird besonders für Substantive verwendet. Um beispielsweise ‚exchange‘ und seine gebeugten Formen zu normalisieren (d.h. ‚exchange‘), verwenden Sie das POS-Tag ‚rule‘ |
|
Unbekannt |
Tag, das vom Translation Engine automatisch für nicht erkannte, nicht analysierbare Einträge vergeben wird |
|
Verb |
Ein Wort, das Existenz, Handlung oder Vorkommen ausdrückt. Verwenden Sie Infinitiv. |
|
Ziel
Die Übersetzung des Eintrags. Klicken Sie auf das Symbol Inflections, um die Biegeinformationen des Eintrags abzurufen
Priorität
Weisen Sie einem Eintrag eine Priorität zwischen 1 (Standard, empfohlen) und 9 (niedrigste Priorität) zu. Dies legt fest, wie der Eintrag im Verhältnis zu anderen Wörterbüchern, einschließlich SYSTRANs Hauptwörterbuch, angewendet wird. Weitere Informationen zu den Prioritäten sind der nachstehenden Tabelle zu entnehmen:
Priorität |
Beschreibung |
|---|---|
1 |
Einträge der Priorität 1 haben Vorrang vor allen anderen Wörterbuchcodierungsregeln. Verwenden Sie diese Priorität sorgfältig, da sie die Hauptübersetzung beeinträchtigen kann, indem sie grammatische Begriffe, allgemeine Ausdrücke oder allgemeine Homographien ausblendet |
2 |
Einträge der Priorität 2 haben Vorrang vor längeren Ausdrücken aus den eingebauten SYSTRAN-Wörterbüchern, aber nicht vor grammatikalischen Begriffen/Regeln (die nur durch Priorität 1 ausgeschlossen werden) |
3 |
Einträge der Priorität 3 haben keinen Vorrang vor längeren Ausdrücken oder grammatikalischen Regeln, und Homographien aus den eingebauten SYSTRAN-Wörterbüchern werden nicht berücksichtigt. Für zwei Einträge mit Priorität 3 entscheidet die Reihenfolge des Wörterbuchs. Beachten Sie, dass längere Ausdrücke mit einer niedrigeren Priorität (4-7) Vorrang vor einem Eintrag mit Priorität 3 haben |
4 - 6 |
Prioritätseinträge 4 - 6 haben keinen Vorrang vor längeren Ausdrücken oder grammatikalischen Regeln und Homografien aus den eingebauten SYSTRAN-Wörterbüchern bleiben erhalten. Die Reihenfolge der Verwendung wird durch die Wörterbuchreihenfolge in den Übersetzungsoptionen festgelegt |
7 |
Einträge der Priorität 7 sollten nur verwendet werden, wenn keine anderen Einträge vorhanden sind, die mit anderen Wörterbüchern übereinstimmen. Diese Priorität wirkt sich nur auf Nicht gefundene Wörter aus |
8 |
Die Priorität 8 sollte niemals Vorrang erhalten, sondern wird in anderen Bedeutungen angezeigt |
9 |
Einträge der Priorität 9 sollten niemals verwendet werden und werden nicht in anderen Bedeutungen angezeigt. Verwenden Sie diese Priorität, um einen Eintrag zu deaktivieren, ohne ihn zu entfernen. Benutzer können diese Priorität auch bei der Verwendung des Operators „Suche“ anwenden, wenn sie nicht möchten, dass ein Unterwörterbuch, auf das im Operator verwiesen wird, übereinstimmt |
Kommentare
Fügt Kommentare zum Eintrag hinzu (z.B.: Hinzugefügtes Datum, Autor des hinzugefügten Eintrags, etc.)
Vertrauen
Gibt die Codierungsqualität des Eintrags an, d. h. wie genau die Übersetzung der Quelle entspricht. Diese Messung ist das Ergebnis eines Vergleichs mit der SYSTRAN Linguistic Resource Database. Je voller die Latte, desto stärker das Vertrauen
Löschen
Löscht die Zeile mit dem Eintrag
Wörterbücher bearbeiten: Bearbeitungszone
Unterhalb der Navigationstabelle befindet sich eine weitere Tabelle (Edition & Log), in der vorhandene Einträge geändert werden können und neue Einträge zum Wörterbuch hinzugefügt werden können.
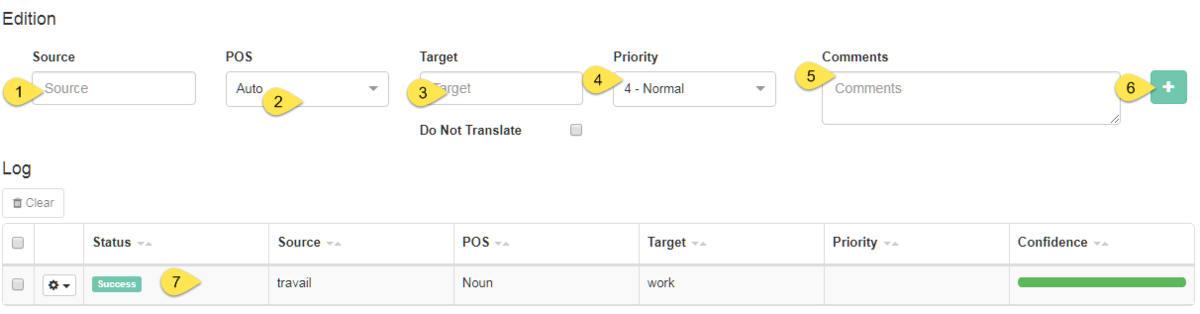
Um einen vorhandenen Eintrag zu ändern, klicken Sie auf die Zeile des Eintrags in der Wörterbuch-Editor-Tabelle, um ihn zu markieren. Es wird in den Feldern am unteren Rand der Seite angezeigt. Wenn kein Eintrag markiert ist, sind diese Felder leer. Sie können einen neuen Eintrag hinzufügen, indem Sie Folgendes eingeben:
Quelle
POS
Zielscheibe
Priorität
Kommentare
Klicken Sie auf Hinzufügen (oder Bearbeiten, wenn ein vorhandener Eintrag geändert wurde)
Wenn ein Eintrag erfolgreich hinzugefügt wurde, wird sein Status als Codierung erfolgreich angezeigt. Wenn dies nicht der Fall ist, wenden Sie sich an Ihren Administrator. Wenn Sie einen neuen Eintrag hinzufügen, wird auch dessen Zuverlässigkeit berechnet und angezeigt
Verwenden Sie bei der Bestimmung des POS das Lemma des Eintrags, sofern es sich nicht um einen Ausdruck oder eine Regel handelt. Standardmäßig erfolgt die Zuweisung eines POS automatisch. Wenn der Eintrag ein echtes Substantiv ist, das nicht übersetzt werden sollte, kreuzen Sie das Kästchen Nicht übersetzen an. Bewegen Sie den Mauszeiger über das Informationssymbol unten rechts auf der Seite, um die Verwendung von Tastenkombinationen zu erfahren.
Wörterbücher herunterladen
Klicken Sie auf Herunterladen
Benennen Sie die heruntergeladene Datei mit der Erweiterung ‚.txt‘ um, um die Datei zu öffnen
Wörterbuchkodierung
Sonderzeichen
Hash # kann nicht verwendet werden
Einige Zeichen müssen geschützt werden:
Anführungszeichen „“ und Klammern „()“ sollten mit einem umgekehrten Schrägstrich „" versehen werden, damit sie als Teil des Eintrags und nicht als Teil der Codesyntax betrachtet werden; sie werden im codierten Eintrag (ohne umgekehrten Schrägstrich) angezeigt
Der umgekehrte Schrägstrich „" muss als „\" eingegeben werden; er wird im kodierten Eintrag als „\“ angezeigt
Die meisten Bindestriche (z. B. Bindestrich „-“, Gedankenstrich „—“ usw.) werden bei der Übersetzungseingabe zu Bindestrichen minus „-“ normalisiert (wenn der Wörterbucheintrag also einen Bindestrich enthält, entspricht er nicht der normalisierten Eingabe)
Die meisten Anführungszeichen werden in der Übersetzungseingabe in einfache Anführungszeichen umgewandelt, während einfache Anführungszeichen in andere (Gebietsschema-)Anführungszeichen in der Ausgabe umgewandelt werden können
Kodierhinweise
Anführungszeichen können verwendet werden, um einen Teil des Eintrags zu fixieren, sodass er sich nicht verändern kann. Die Anführungszeichen werden im kodierten Eintrag nicht angezeigt
Kodierhinweise in Klammern für Zahl (SG, PL), Geschlecht (M, F, Neuter) und andere morpho-syntaktische Informationen können für bestimmte Sprachen verwendet werden
Normalisierungen
Mithilfe von Normalisierungswörterbüchern (NDs) kann der Text vor und nach der Übersetzung reguliert werden, was zur Standardisierung der Terminologie und zur Erweiterung von Abkürzungen und Akronymen beiträgt. NDs können auch verwendet werden, um Rechtschreibfehler zu standardisieren und eine gemeinsame Terminologie zu erstellen (z. B. Fälle, in denen zwei oder mehr Wörter für dasselbe Konzept verwendet werden).
Sie können einem Profil Normalisierungswörterbücher hinzufügen (entweder für die Ausgangssprache oder für die Zielsprache). Falls für die Ausgangssprache ein Normalisierungswörterbuch angegeben ist, wird das Ausgangswörterbuch vor der Übersetzung verarbeitet. Wenn das Normalisierungswörterbuch für die Zielsprache festgelegt ist, wird der übersetzte Text verarbeitet.
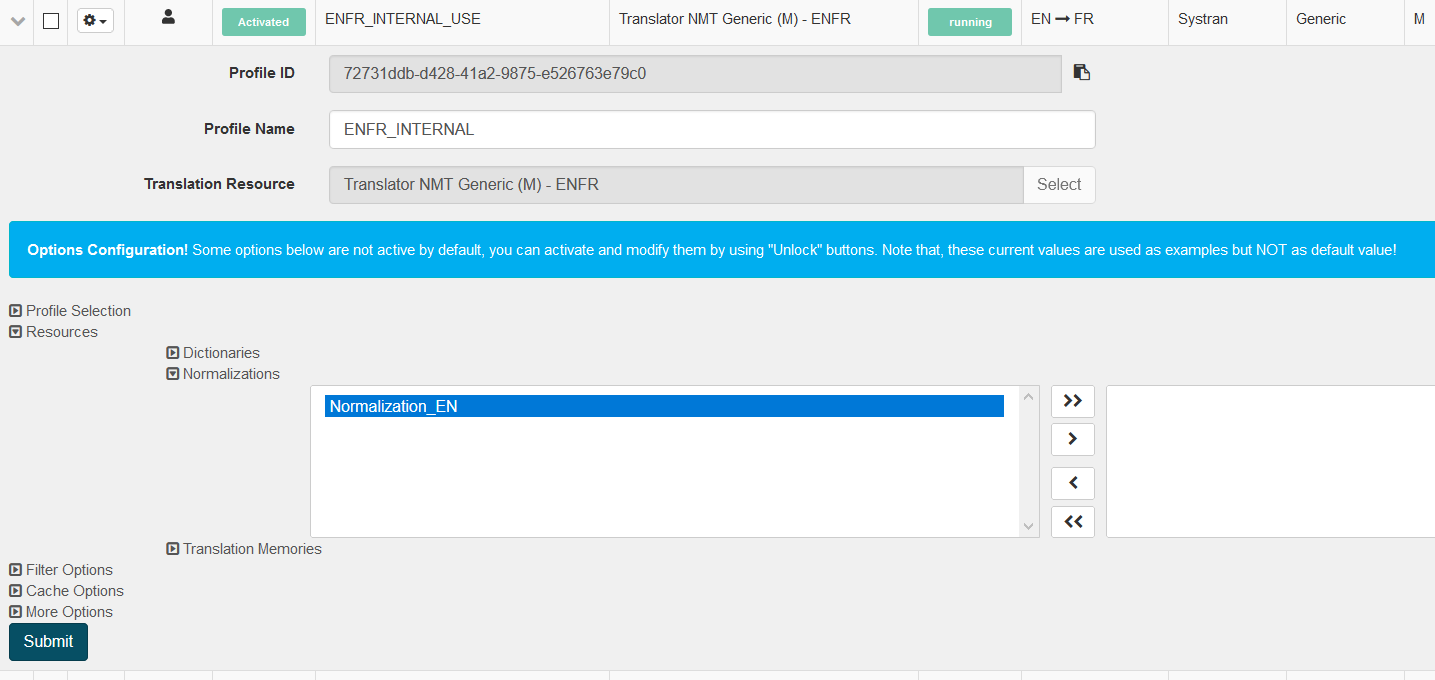
Um ein neues Normalisierungswörterbuch zu erstellen, klicken Sie in Resources auf Normalizations und dann auf Create, um ein Dialogfeld zu öffnen:
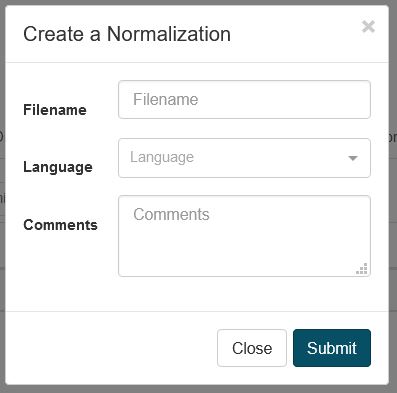
Wählen Sie einen Namen für das Normalisierungswörterbuch und die Sprache aus
Klicken Sie auf Absenden, um das Normalisierungswörterbuch zu erstellen
Für das Hochladen, Herunterladen und Bearbeiten von Normalisierungswörterbüchern gelten dieselben Richtlinien wie für Benutzerwörterbücher. Siehe obigen Abschnitt zu Wörterbüchern.
Stellen Sie beim Importieren eines neuen Normalisierungswörterbuchs sicher, dass die Überschrift das richtige Format hat. Die folgende Beispieltextdatei wurde für den Import eines Normalisierungswörterbuchs in SYSTRAN Translate formatiert. Beachten Sie, dass <TAB> das Tabulatorzeichen angibt.
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#SUMMARY=EN NORMALIZATION DICTIONARY
#ENCODING=UTF-8
#COVERED DOMAINS=coll
#GENERAL DICTIONARY DOMAINS=coll
#NORM
#EN EN_NO UPOS DOMAINS NOTE
youre <TAB> you are <TAB> sequence
4ever <TAB> forever <TAB> sequence
Nachdem Sie ein Normalisierungswörterbuch erstellt oder importiert haben, können Sie es einem Profil zuordnen.
Translation Memorys
Translation Memorys (TMs) sind nützlich, um die Konsistenz der Übersetzungen in einer Vielzahl dokumentierter Dateien zu gewährleisten. TMs sind Sammlungen von Satzpaaren, die jeweils einen ausgangssprachlichen Satz und dessen Übersetzung enthalten und in einer zwei- oder mehrsprachigen Datenbank gespeichert sind. Durch die Verwendung eines Translation Memory können Wörter oder Ausdrücke aus bereits übersetzten Texten während des Übersetzungsprozesses abgerufen werden. Im Gegensatz zu Einträgen in eigenen Wörterbüchern - die sprachlich unbedenklich bleiben - sind die Satzübersetzungen in TMs statisch. Wenn Sie ein Dokument mit einem Profil übersetzen, das TMs enthält, werden die Sätze, die sich im Speicher befinden (exakte Übereinstimmungen), von der maschinellen Übersetzung überschrieben. Anstatt diesen Satz neu zu übersetzen, setzt SYSTRAN einfach den entsprechenden bereits übersetzten Zielsatz in das Dokument ein.
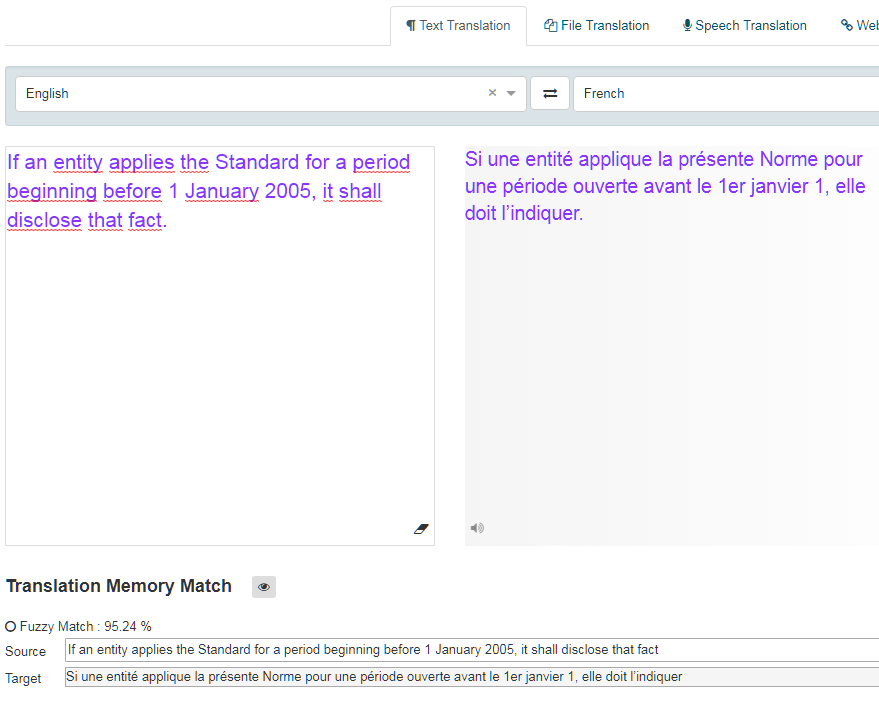
Bei der Übersetzung mit einem Translation Memory entspricht ein Segment im Ausgangstext, das genau einem Segment in der Translation-Memory-Datenbank entspricht, einer genauen Übereinstimmung mit einer Bewertung von 1,0 (100 %), und ein Segment, das teilweise übereinstimmt, ist eine Fuzzy-Übereinstimmung mit einem Wert kleiner als 1 (<100 %). Die Bewertung vergleicht die Eingabe mit der Übereinstimmung im Translation Memory und berechnet die Ähnlichkeiten zwischen den beiden. Je höher die Punktzahl, desto enger ist das Spiel. Die Datenbank gibt alle Übereinstimmungen zurück, die über dem vom Administrator konfigurierten Fuzzy-Match-Schwellenwert liegen (standardmäßig 70 %). Diese Übereinstimmungen werden bei der Überprüfung einer Übersetzungsdatei im Textübersetzungstool und im Übersetzungseditor als Fuzzy-Match-Alternativen angezeigt.
Im Feld Textübersetzung wird der Fuzzy Match grün hervorgehoben und die Punktzahl angezeigt.
Darüber hinaus können Translation Memorys als Test-, Tuning- oder Schulungskorpus in Ihren Schulungsprojekten verwendet werden.
Erstellung von Translation Memories
Translation Memorys erstellen
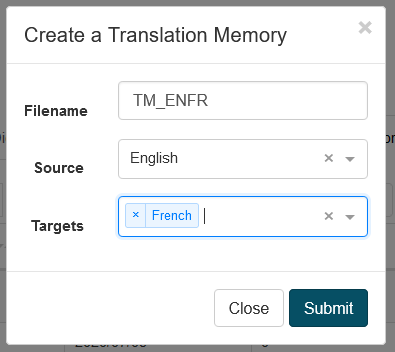
Um ein Translation Memory zu erstellen, klicken Sie auf die Schaltfläche Erstellen. Anschließend müssen Sie einen Dateinamen, eine Ausgangssprache und eine Zielsprache eingeben.
Hochladen eines Translation Memory
Translation Memory eXchange (TMX)-Dateien sind eine XML-Spezifikation. SYSTRAN Translate unterstützt TMX-Versionen zwischen 1.2 und 1.4. Weitere Informationen finden Sie unter Localization Industry Standards Association’s TMX page.
Um ein Translation Memory hochzuladen, klicken Sie auf Resources, dann auf Translation Memory, wählen Sie das gewünschte Translation Memory aus und klicken Sie auf ‚Edit‘. Klicken Sie auf „Anfügen“ Ein Dialogfenster erscheint:
Nach dem Hochladen werden die Einträge des Translation Memory auf der Seite Translation Memory angezeigt.
Bemerkung
Wir empfehlen, TM hochzuladen, die 200000 Segmente nicht überschreitet.
So verwenden Sie ein Translation Memory mit einem Profil:
Klicken Sie auf Profile
Profile auswählen
Erweitern Sie die Profiloptionen
Wählen Sie unter Ressourcen das gewünschte Translation Memory aus
Klicken Sie auf Absenden
Translation Memory-Editor
Wechseln Sie zu Resources > Translation Memories
Klicken Sie auf Bearbeiten
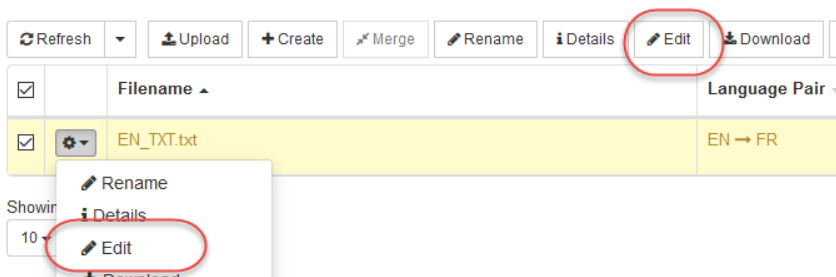
Der Translation Memory Editor wird geöffnet
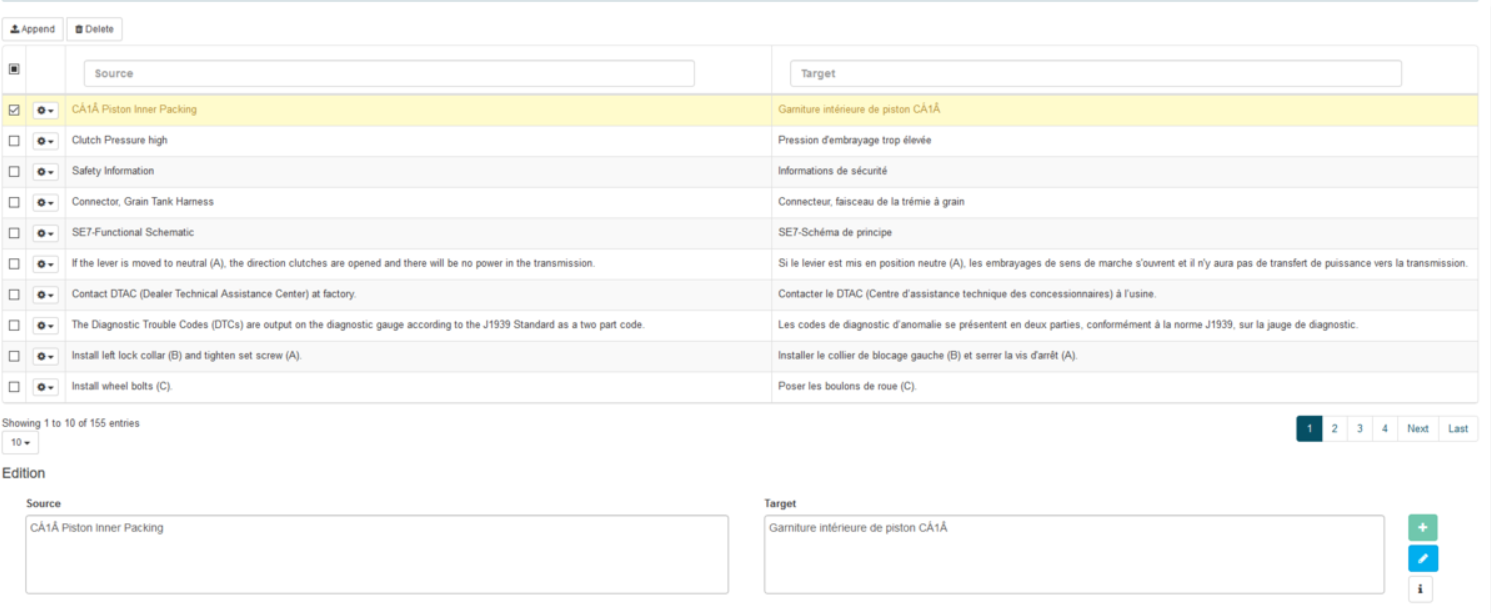
Satz bearbeiten
Eintrag auswählen
Aktualisieren der erforderlichen Felder (Quelle und/oder Ziel)
Klicken Sie auf den Button „Bearbeiten“ oder drücken Sie die Eingabetaste auf der Tastatur
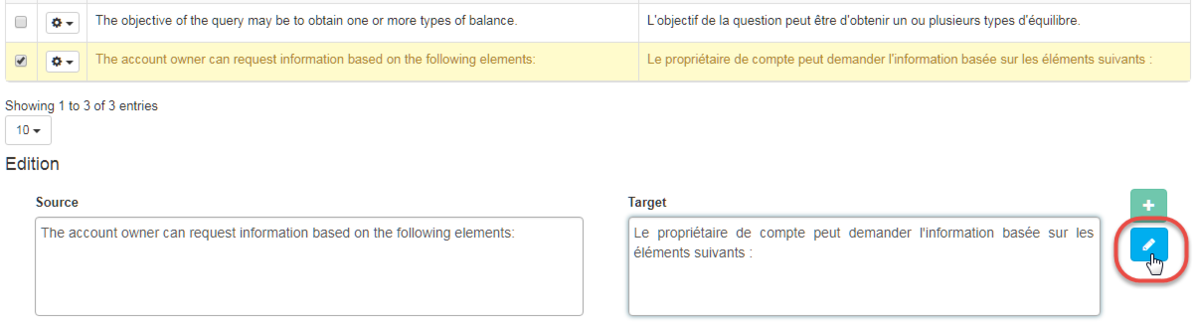
Hinzufügen eines neuen Segments zum Translation Memory
Sie können einen Eintrag direkt über die Quell- und Zielfelder hinzufügen:


Einen Satz durchsuchen
Um nach bestimmten Sätzen zu suchen, geben Sie das gesuchte Wort oder den gesuchten Satz in das Feld Ausgangs- oder Zielsegment ein:
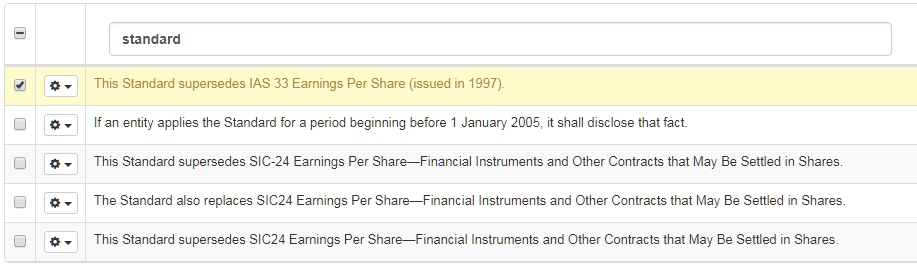
Segment löschen
Segment auswählen
Klicken Sie auf Löschen
Klicken Sie auf Absenden, um den Löschvorgang zu bestätigen