リソース管理
systran翻訳では、**Resources**メニューから様々な言語資料を管理できます。
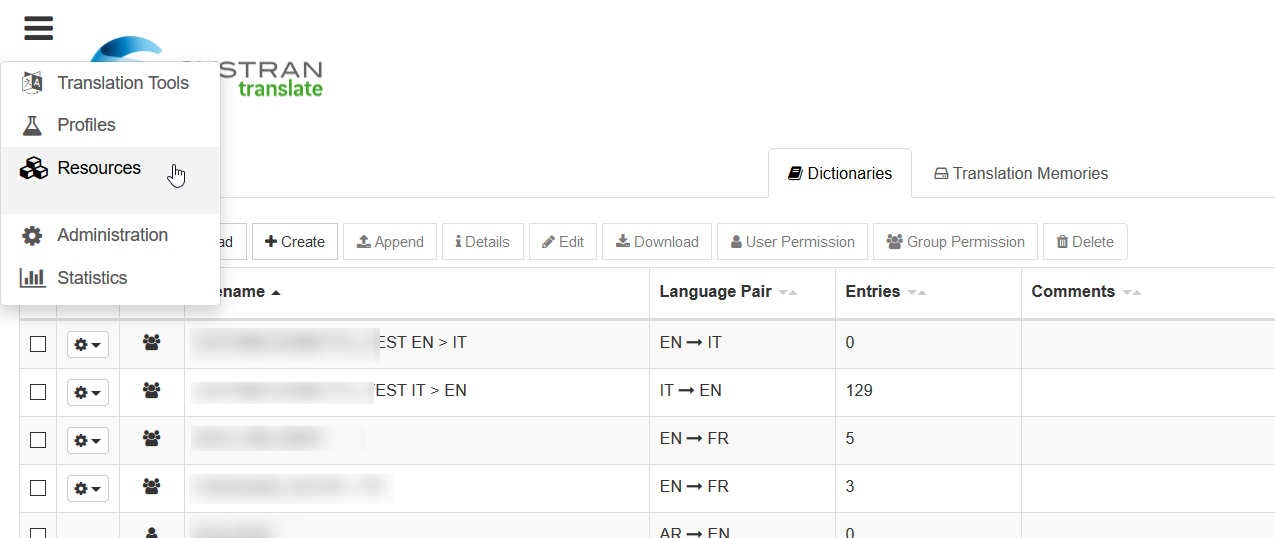
これにより、ユーザーは翻訳のニーズに合わせて強力な言語リソースを実装できます。ユーザーは、翻訳メモリやドメイン辞書などの辞書をプロファイルに追加して、翻訳を向上させることができます。
リソースが完了したら、「プロフィール」ページからプロフィールに追加できます。
注釈
UDおよびTMは、ピボットプロファイルでは使用できません。
アクセス許可
特定のユーザーまたはグループと次の要素を共有できます。
ユーザー辞書
翻訳メモリ
各アイテムについて、「ユーザー権限」または「グループ権限」ボタンをクリックして、権限の割り当てポップアップを開きます。
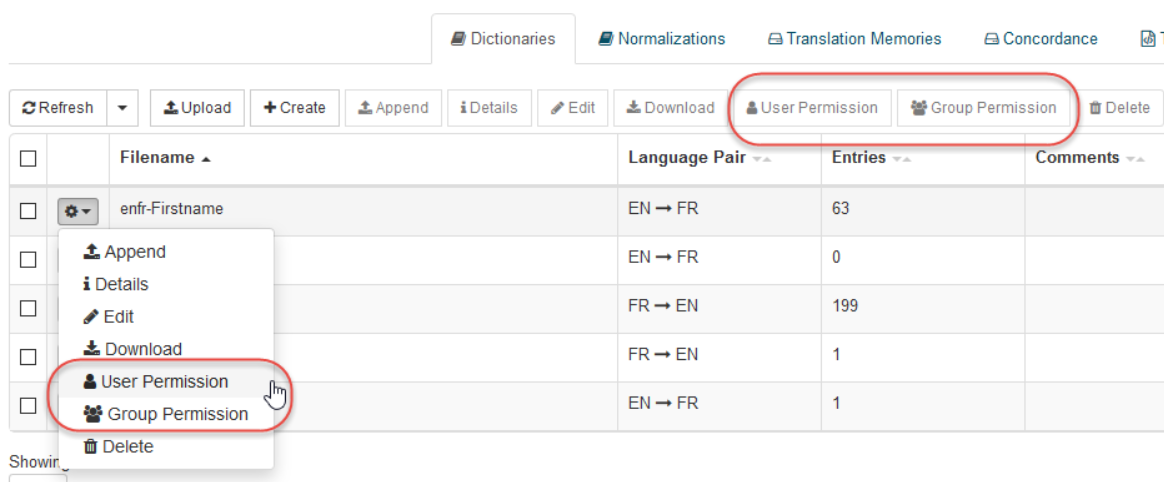
アクセス許可ポップアップを開いたら、ユーザー名またはグループ名を選択して、ユーザー/グループレベルでアクセス許可を割り当てることができます。次に、
ユーザー/グループに関連付けられたツールバーまたはドロップダウンメニューから適切なアクセス権を選択します(詳細は以下を参照)
指定したユーザーの「保存」をクリックします
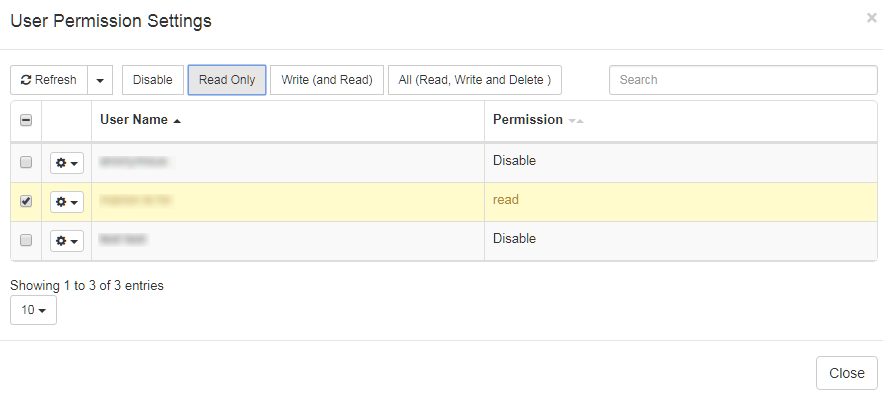
ユーザーまたはグループには、次の権限を付与できます。
無効: (既定)アイテムが表示されません**読み取り専用**:
アイテムは、リストから読み取り専用モードで入力できます(ユーザーがTranslation Memoryメニューなどのリソースリストへのアクセス権を持っている場合)
アイテムはプロファイル内でユーザーが選択できます(ユーザーがプロファイルを作成する権限を持っている場合)
このアイテムは、'テキスト翻訳'ツールのルックアップ結果に含まれます(つまり、辞書または翻訳メモリにある要素は、辞書ルックアップボックスまたは翻訳メモリのルックアップ結果に表示されます)
Write' (およびRead):上記と同じ権限に加えて、
ユーザーはリソースを入力および変更できます
すべて(読み取り、書き込み、および削除):上記と同じ権限に加えて、
ユーザーはアイテムを削除したり、他のユーザーに対するアイテムのアクセス許可を設定したりすることもできます
また、今後のバージョンでは、プロファイルとアクティブプロファイルにもアクセス許可メカニズムが実装される予定です。
辞書
ユーザ辞書をプロファイルに割り当てて、翻訳の品質を向上させることができます。翻訳ソフトウェアの品質は、システムが達成する「理解」のレベルに直接結びついています。「理解」を深めるためには、文章の構文解析だけでなく、意味解析も正しく行う必要があります。これは、使用される意味文脈によって意味や構文挙動が異なる単語があるためです。ユーザー辞書の項目は、翻訳プロセス中にSystranのメイン辞書に含まれる100万以上の組み込み項目を上書きします。
ディクショナリの更新
「辞書」リストから辞書に対して次のアクションを実行できます。
追加 →ファイルをアップロードしてエントリを追加します。詳細は以下を参照してください
編集 →エントリを追加および編集します。詳細は以下を参照してください
詳細 →辞書のプロパティ(名前、ソース、ターゲット言語)を変更し、コメントを追加または編集します
ダウンロード →辞書をダウンロードします
辞書のアップロード
辞書にエントリをアップロードするには、辞書を選択し、「追加」ボタンをクリックし、バイナリ形式(.dct)、Microsoft Excel(.xls)、またはプレーンテキスト(.txt)に従って辞書をアップロードします。
注釈
200000セグメントを超えないUDのアップロードをお勧めします。
Microsoft Excelなどのスプレッドシートアプリケーションまたは一般的なテキストエディタで作成した辞書は、インポートする前に注意深くフォーマットする必要があります。以下に、辞書のインポートに必要なフォーマットについて詳しく説明します。
Microsoft Excelファイル
Microsoft Excelで作成された辞書をインポートするには、ファイルが1つの翻訳に対して1つのワークシート(英語からフランス語など)で構成されている必要があります。書式設定されたテキスト・ファイルと同様に、UDの「言語」列および「情報」列のMicrosoft Excelファイル列見出しは、2文字のISO 639コード言語を大文字にして入力する必要があります。
書式付きテキストファイル
systran翻訳用にインポートするフォーマット済みテキストファイルには、ドキュメントヘッダーと辞書コンテンツが含まれます。辞書のヘッダは「#」文字で始まり、ヘッダフィールドの後にその値が続く一連の行です。辞書の内容は一連の行で、各行はタブ文字で区切られたフィールドを持つ辞書エントリを表します。フィールドの型はヘッダーで定義されます。各行のフィールド数は、空の場合でも同じにすることが重要です。
SYSTRAN変換にファイルをアップロードするための必須フィールドとオプションフィールド:
ヘッダー |
入力の説明 |
|---|---|
#COVEREDドメイン= |
オプションのヘッダー:辞書で構成されているすべてのドメインを一覧表示します
注: NMTには適用されません
|
#ENCODING= |
必須:ファイルのエンコーディングを定義します。UTF-8エンコードを推奨します |
#GENERALディクショナリドメイン= |
オプションのヘッダー:ディクショナリに関連付けられたシステム・ドメインがリストされます。
注: NMTには適用されません
|
#SUMMARY= |
必須: UDファイル名 |
#MULTI/TM/NORM/DNT #<言語><情報列>= |
必須:この2行はヘッダー・セクションの最後です。 #MULTIは、辞書がユーザー辞書であることを定義します #TMは、辞書が翻訳メモリであることを定義します #NORMは、辞書が正規化辞書であることを定義します #DNTは、ユーザ辞書でDNTエントリから多言語エントリを分離するために使用されます 2行目は、コンテンツセクションの列のリストを示します。次の表に示すように、タブ文字で区切られたコードのリストです |
コンテンツフィールドを定義する別のコードの説明
コード |
説明 |
|---|---|
XX |
ここで、XXは大文字の2文字のISO 639コードです。これは言語を表します(付録B言語ペアとISO 639を参照してください)
ソース言語は常に最初のカラムで、ターゲット言語は次のカラムです
|
XX_NO |
正規化辞書のみ。XXはソース言語のISO 639コードに対応します。これらの列は次を表します。
正規化された列
|
UPOS |
ユーザーの品詞。使用できるPOS:頭字語、形容詞、副詞、接続詞、名詞、前置詞、固有名詞、規則、動詞 (小文字で綴られる)。
これらは*Expression*を除き、インターフェイス内のPOSに対応します。
|
見出し語_XX |
この列は、エクスポートの実行時に生成されます。対応するXXフィールドの見出し語を含みます。
インポート中は、この列は無視されます
|
優先権 |
「優先度」列
注: NMTには適用されません
|
ドメイン |
[ドメイン]列:ドメインはコンマで区切ります
注: NMTには適用されません
|
頻度 |
「頻度」列 |
例 |
列の例 |
サンプル形式のテキストファイル:
次のサンプルテキストファイルは、ユーザー辞書としてSYSTRAN翻訳に読み込めるようにフォーマットされています。<TAB>はタブ文字を示します。
#ENCODING=UTF-8
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#COVERED DOMAINS=Computers/Data Processing,Perso
#GENERAL DICTIONARY DOMAINS=Computers/Data Processing
#PRIORITY=1
#SUMMARY=Demo Computer
#MULTI
#EN<TAB>FR<TAB>NOTE<TAB>DOMAINS<TAB>PRIORITY<TAB>UPOS
white cycle<TAB>cycle d'écriture<TAB>Note<TAB>1<TAB>noun
write enable<TAB>validation écriture<TAB><TAB><TAB>noun
#DNT
#EN<TAB>NOTE<TAB>DOMAINS
Print 2000<TAB>It is a DNT<TAB>Perso
次のサンプルテキストファイルは、翻訳メモリとしてSDMにインポートできるようにフォーマットされています。
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#ENCODING=UTF-8
#SUMMARY=Demo
#TM
#EN<TAB>FR<TAB>DE
My name is Smith<TAB>Mon nom est Smith<TAB>Mein Name ist Smith
プロファイルでユーザー辞書を使用するには、次の手順に従います。
プロフィールをクリックします
プロファイルを選択します
プロファイルオプションを展開します
「リソース」で、必要なディクショナリを選択します
[送信]をクリックします
インポートされた辞書のエントリは、[編集**をクリックしてサーバー上で直接変更でき**す。このツールの使用方法の詳細は以下のとおりです。
辞書の編集:ナビゲーションテーブル
**編集**をクリックして、辞書エディタツールにアクセスします。
これにより、エントリを表示、変更、追加、削除できるテーブル形式の辞書を表示する新しいページが開きます。列見出し(ソース、POS、ターゲット、優先度、コメント、信頼度)に基づいてアルファベット順に並べ替えることで、辞書エントリをフィルタできます。追加のフィルタは、列ヘッダーの下にある検索ボックスにキーワードを入力することで実行できます。
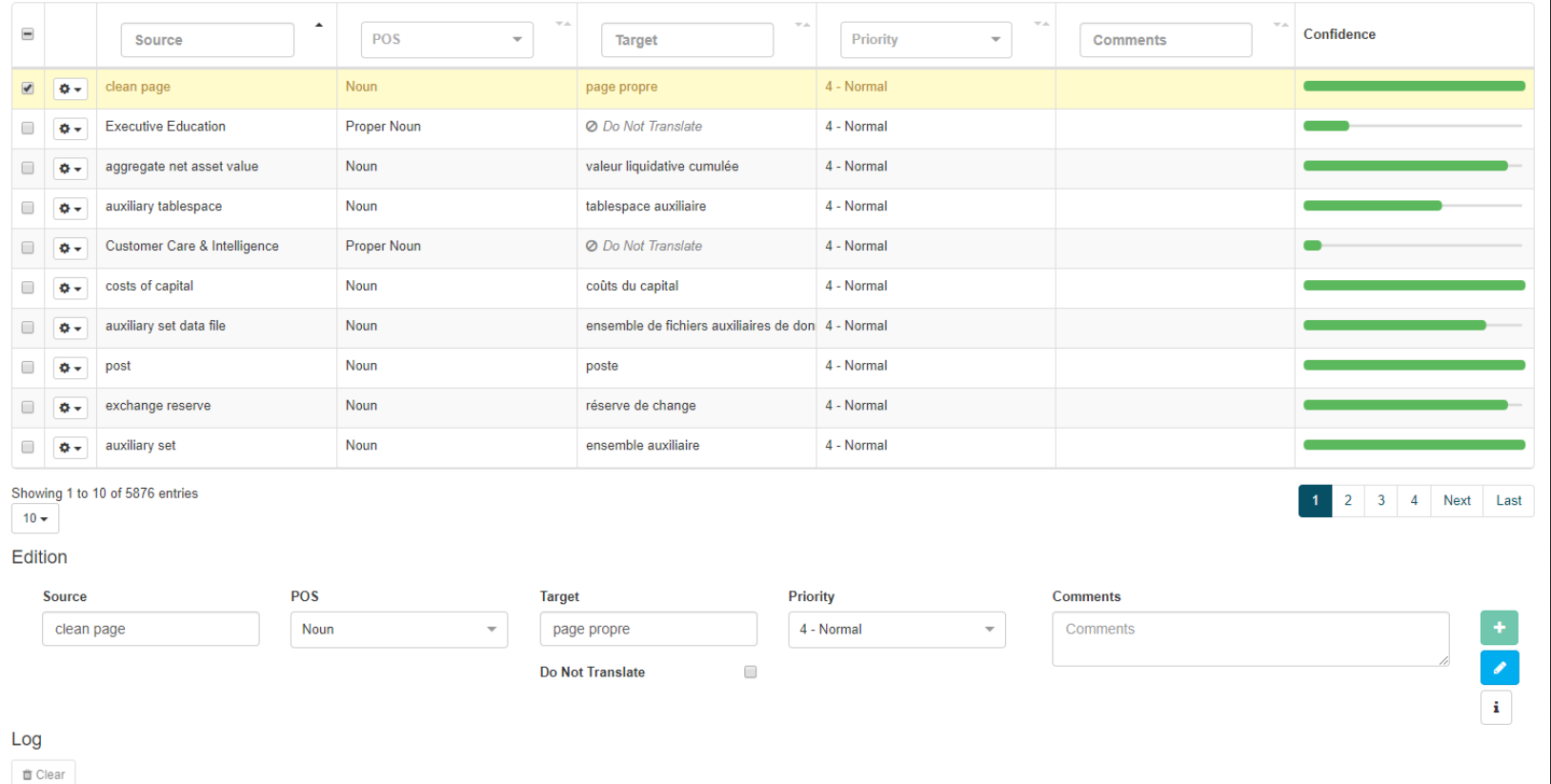
このページでは、各辞書エントリについて次の情報を表示できます。
ソース
辞書の各シングルワードまたはマルチワードのエントリは、この列の下に1行ずつ表示されます。**Inflections**アイコンをクリックして、エントリの変更情報を取得します
位置
ソースエントリの品詞。次の表に、スピーチの構成要素を示します。
位置 |
説明 |
例 |
|---|---|---|
頭文字 |
systran用語で,他の単語の最初の文字または一連の単語の一部から形成される単語(すべて大文字) |
|
形容詞 |
名詞や代名詞を修飾する語。ブロックとして保持する必要があり、変更されない(二重引用符で囲む)マルチワードシーケンスを含むエントリが含まれます |
|
副詞 |
動詞、節、形容詞を修飾する単語。複数の単語のシーケンスをブロックとして保持し、変更しない(二重引用符で囲む)場合に使用できます |
|
接続詞 |
コネクタとして使用される単語。注意:このPOSを使用しないことを強くお勧めします |
|
式 |
systran用語で、複数の名詞から成る名詞句、または名詞と形容詞の任意の組み合わせで構成される名詞句。見出し語は名詞です。動詞を含む完全な文または句は無効です |
|
能雲 |
人、場所、物、品質、動作などの名前を指定するために使う単語です。小文字と大文字をすべて区別し、単語が変更されないようにするには、小文字を使います |
|
前置詞 |
名詞または名詞句の前に置かれる単語。動詞、形容詞、または別の名詞または名詞句に対するその名詞または名詞句の関係を示します。注意:このPOSの使用は強くお勧めします |
|
固有名詞 |
人、会社、場所などに使われる語のクラスに属する名詞エントリは変更されません。すべての大文字と小文字を区別する場合は、小文字を使用します |
|
規則 |
正規化ディクショナリで、エントリとその変更済みフォームを一致させるために使用します。特に名詞に用いられる。例えば、'excahnge'とその展開されたフォーム(例: 'excahnges')を正規化するには、POSタグ'rule'を使用します |
|
不明 |
分析できない認識できないエントリに対して、翻訳エンジンによって自動的にタグ付けされます |
|
動詞 |
存在、動作、または発生を表す単語。不定詞を使え。 |
|
ターゲット
エントリの翻訳。**Inflections**アイコンをクリックして、エントリの変更情報を取得します
優先度
1 (デフォルト、推奨)から9 (最低の優先度)の範囲のエントリに優先度を割り当てます。systranのメイン辞書を含む他の辞書に対して、この項目をどのように適用するかを指定します。優先順位の詳細については、次の表を参照してください。
優先度 |
説明 |
|---|---|
1 |
優先度1のエントリは、他の辞書コーディング規則よりも優先されます。この優先度は慎重に使用してください。文法用語、共通表現、または共通ホモグラフを隠すことによって主翻訳を劣化させる可能性があります |
2 |
優先度2の項目は、SYSTRANの組み込み辞書からのより長い式よりも優先されますが、文法的な用語/規則よりも優先されません(優先度1によって除外されているもののみ) |
3 |
優先度3の項目は長い式や文法規則よりも優先されず、組み込み辞書のSYSTRANからの同義語は考慮されません。優先度3の2つのエントリについては、辞書順で決定されます。優先度3のエントリよりも優先度の低い長い式(4-7)が優先されます |
4 - 6 |
優先度の項目4~6は、長い式や文法規則に優先せず、組み込み辞書が保持されるSYSTRANからの同義語も保持されます。使用する順序は、「翻訳オプション」で設定した辞書順序によって定義されます |
7 |
優先度7の項目は、他の辞書と一致する項目が他にない場合にのみ使用してください。この優先度は見つからない単語にのみ影響します |
8 |
優先度8の項目は優先されるべきではないが、代わりの意味で表示される |
9 |
優先度9のエントリは決して使用してはならず、代わりの意味で表示されることはありません。この優先順位を使用して、エントリを削除せずに無効にします。ユーザーは、検索演算子で参照されるサブ辞書を一致させたくない場合は、検索演算子を使用するときにこの優先順位を適用することもできます |
コメント
エントリに関するコメントを追加します(例:追加された日付、追加されたエントリの作成者など)
信頼
エントリのコーディングの質を示します。これは、ソースに対する翻訳の対応度を示します。この数値は、SYSTRAN言語資源データベースと比較した結果です。バーが充実すればするほど、自信が強くなる
削除
エントリを含む行を削除します
辞書の編集:ゾーンの編集
ナビゲーションテーブルの下には、既存のエントリを変更したり、新しいエントリを辞書に追加したりできる別のテーブル(エディションとログ)があります。
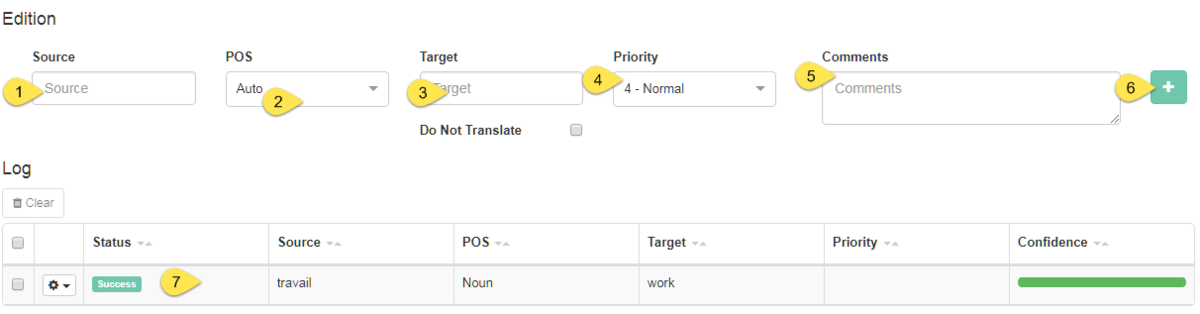
既存のエントリを変更するには、辞書エディタテーブルでエントリの行をクリックしてハイライト表示します。ページ下部のフィールドに表示されます。強調表示されているエントリがない場合、これらのフィールドは空白になり、次のように入力して新しいエントリを追加できます。
ソース
位置
目標
優先度
コメント
「追加」(Add) (既存のエントリを変更する場合は「編集」(Edit))をクリックします
エントリが正常に追加されると、そのステータスは「コーディングが完了しました」と表示されます。そうでない場合は、管理者に問い合わせてください。新しいエントリを追加すると、その信頼度も計算されて表示されます
**POS**を決定する場合は、式または規則に関する場合を除き、エントリの補題を使用します。デフォルトでは、POSの割り当ては自動的に行われます。エントリが変換できない固有名詞の場合は、[変換しない]チェックボックスをオンにします。ページの右下にある情報アイコンにカーソルを合わせると、キーボードショートカットの使用方法が表示されます。
辞書のダウンロード
[ダウンロード]をクリックします
ダウンロードしたファイルの拡張子を「.txt」に変更して、ファイルを開きます
辞書符号化
特殊文字
ハッシュ#は使用できません
一部の文字を保護する必要があります:
引用符「」と丸括弧「()」の前にはバックスラッシュ「」を付ける必要があります。これにより、これらの部分はコーディング構文の一部ではなく、エントリの一部とみなされます。これらの部分はコーディングされたエントリに(バックスラッシュなしで)表示されます
バックスラッシュ「」は「\」として入力する必要があります。これはコード化されたエントリでは「\」として表示されます
ほとんどのダッシュ(「 – 」、「 – 」など)は、変換入力ではハイフンから「 – 」を引いた値に正規化されることに注意してください(したがって、辞書エントリにダッシュが含まれている場合、正規化された入力に一致しません)
ほとんどのクォートはトランスレーション入力の中で真っ直ぐなクォートに正規化され、真っ直ぐなクォートは出力の中で他の(ロケールの)クォートに正規化されます
手がかりの符号化
引用符「」」は、エントリを固定(一部)して変更しないようにできます。引用符はコード化されたエントリには表示されません
数字(sg,pl)、性別(m,f,neuter)、その他のモルフォ構文情報を括弧で囲んだ手がかりは、特定の言語で使用できます
正規化
正規化ディクショナリ(ND)は、翻訳前と翻訳後の両方のテキストを調整する方法を提供し、用語を標準化して略語や頭字語を拡張する手段として機能します。NDは、スペルを標準化し、共通の用語を確立するために使用することもできます(例えば、同じ概念に2つ以上の単語が使用されている場合)。
正規化辞書(ソース言語またはターゲット言語)をプロファイルに追加できます。ソース言語に正規化辞書が指定されている場合は、変換前にソース入力テキストが処理されます。ターゲット言語の正規化辞書の場合、翻訳されたテキストが処理されます。
新しい正規化ディクショナリを作成するには、**リソース**で**正規化**次に**作成**をクリックしてダイアログボックスを開きます。
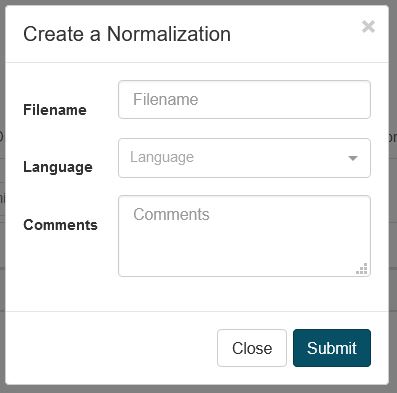
正規化辞書の名前を選択し、言語を選択します
「送信」をクリックして正規化ディクショナリを作成します
正規化ディクショナリのアップロード、ダウンロード、および編集には、ユーザ辞書と同じガイドラインが適用されます。辞書に関する上記のセクションを参照してください。
新しい正規化辞書をインポートする場合は、ヘッダーの形式が正しいことを確認してください。次のサンプルテキストファイルは、正規化ディクショナリをSYSTRAN変換に読み込むためにフォーマットされています。<TAB>はタブ文字を示します。
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#SUMMARY=EN NORMALIZATION DICTIONARY
#ENCODING=UTF-8
#COVERED DOMAINS=coll
#GENERAL DICTIONARY DOMAINS=coll
#NORM
#EN EN_NO UPOS DOMAINS NOTE
youre <TAB> you are <TAB> sequence
4ever <TAB> forever <TAB> sequence
正規化ディクショナリを作成またはインポートすると、そのディクショナリをプロファイルに関連付けることができます。
翻訳メモリ
翻訳メモリ(TM)は、ドキュメント化された一連のファイル間で翻訳の一貫性を確立するのに役立ちます。TMは文のペアのコレクションで、それぞれが原文と翻訳を含み、バイリンガルまたは多言語のデータベースに保存されます。翻訳メモリを使用すると、翻訳プロセス中に前に翻訳されたテキストから単語や式を取得できます。言語分析の影響を受けやすいユーザー辞書エントリとは異なり、TMに存在する文の翻訳は静的です。TMを含むプロファイルを使用して文書を翻訳する場合、メモリ内に存在する文(完全一致)は機械翻訳を上書きします。systranでは、その文を再翻訳するのではなく、すでに翻訳されている対象の文を文書に関連付けるだけです。
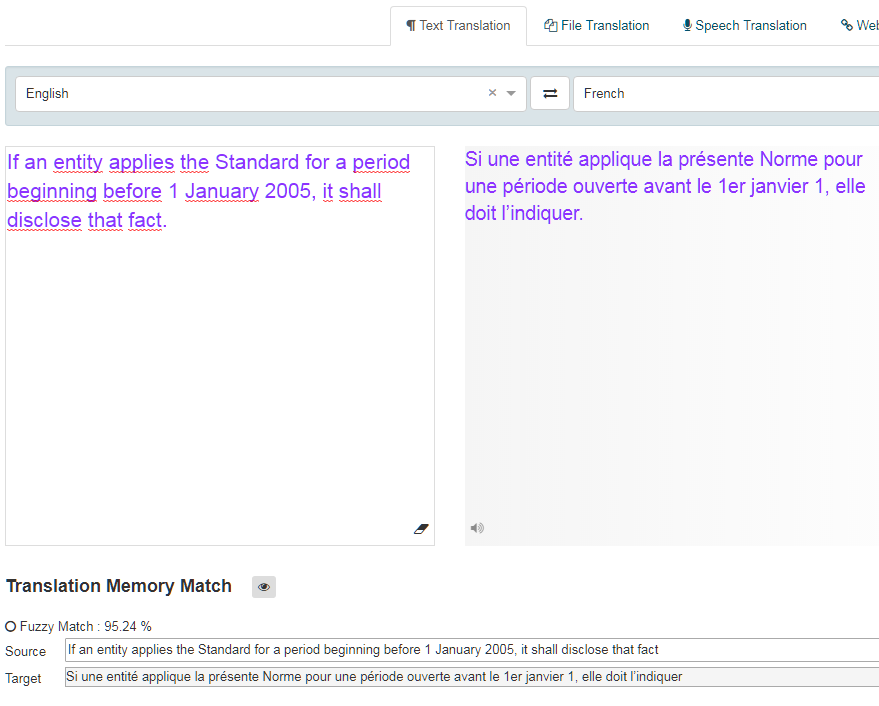
翻訳メモリを使用して翻訳する場合、翻訳メモリデータベースのセグメントに正確に対応するソーステキストのセグメントは、スコアが1.0 (100%)の完全な一致であり、部分的に対応するセグメントは、値が1 (<100%)より小さいあいまい一致です。スコアは入力と翻訳メモリの一致を比較し、2つの類似点を計算します。スコアが高いほどマッチが近くなります。データベースは、管理者が設定したあいまい一致しきい値(デフォルトでは70%)よりも大きい一致を返します。これらの一致は、ファイル翻訳を確認するときに、テキスト翻訳ツールと翻訳エディタであいまいな一致の選択肢として表示されます。
テキスト変換ボックスでは、あいまい一致が緑色でハイライトされ、スコアが表示されます。
また、翻訳トレーニングプロジェクトのテスト、チューニング、またはトレーニングコーパスとして翻訳メモリを使用することもできます。
翻訳メモリの作成
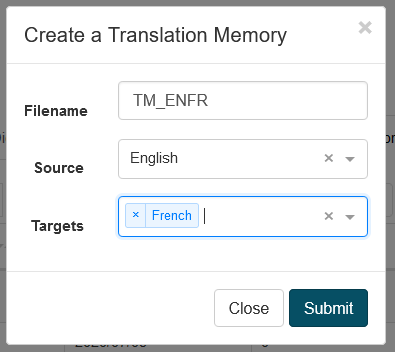
翻訳メモリの作成
翻訳メモリを作成するには、作成ボタンをクリックし、TMファイル名、ソース言語、ターゲット言語をファイルする必要があります。
翻訳メモリのアップロード
翻訳メモリeXchange (TMX)ファイルはXMLの仕様です。SYSTRAN変換は1.2から1.4のTMXバージョンをサポートします。詳細については、「Localization Industry Standards AssociationのTMXページ<https://www.gala-global.org/lisa-oscar-standards/>」を参照してください。
翻訳メモリをアップロードするには、**Resources**をクリックし、**Translation Memory**をクリックして、必要な翻訳メモリを選択し、[編集]をクリックします。「追加」をクリックします。ダイアログボックスが表示されます。
アップロードすると、翻訳メモリのエントリが**翻訳メモリ**ページに表示されます。
注釈
200000セグメントを超えないTMをアップロードすることをお勧めします。
プロファイルで翻訳メモリを使用するには
プロフィールをクリックします
プロファイルを選択します
プロファイルオプションを展開します
[リソース]で、必要な翻訳メモリを選択します
[送信]をクリックします
翻訳メモリエディタ
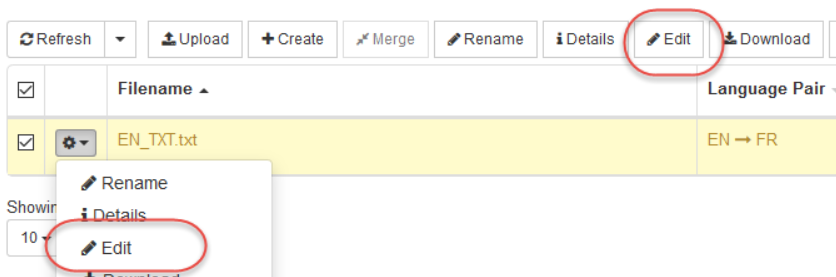
文を編集する
エントリを選択します
必須フィールド(ソースまたはターゲット)の更新
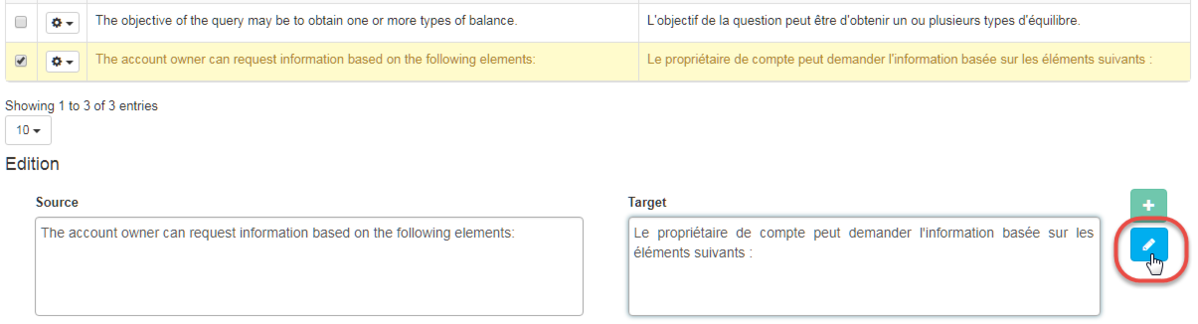
「編集」ボタンをクリックするか、キーボードのEnterキーを押します
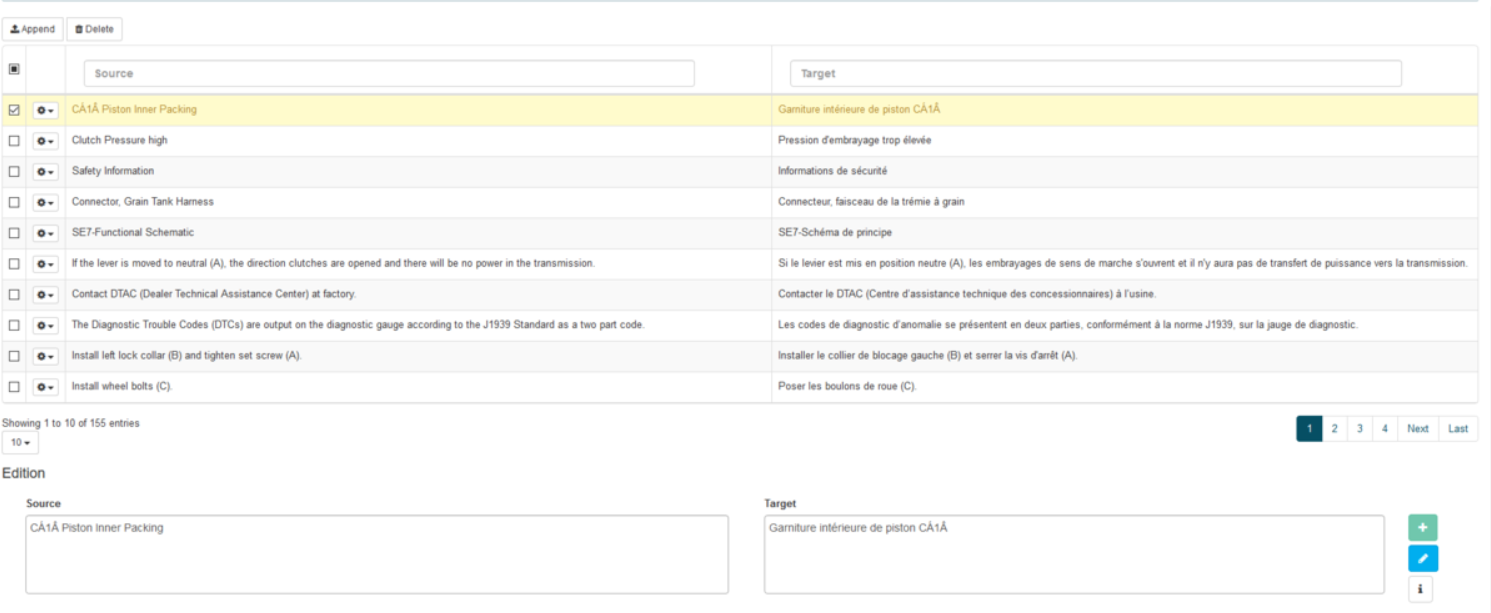
翻訳メモリに新しいセグメントを追加する
ソース・フィールドとターゲット・フィールドを使用して、エントリを直接追加できます。


文章を検索する
特定の文を検索するには、検索する単語または文を「ソース」または「ターゲット」セグメントフィールドに入力します。
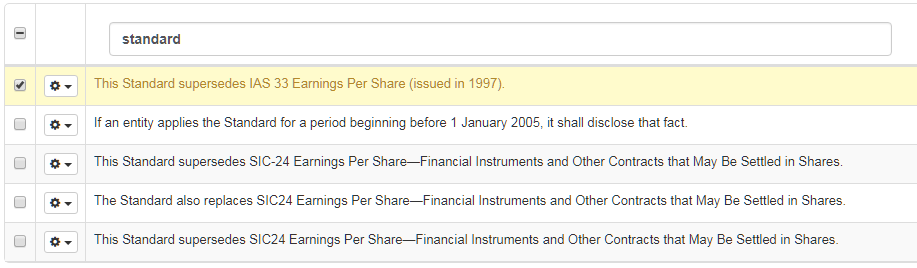
セグメントを削除