Gestion des ressources
Une variété de ressources linguistiques peuvent être gérées dans SYSTRAN Translate via le menu Resources.
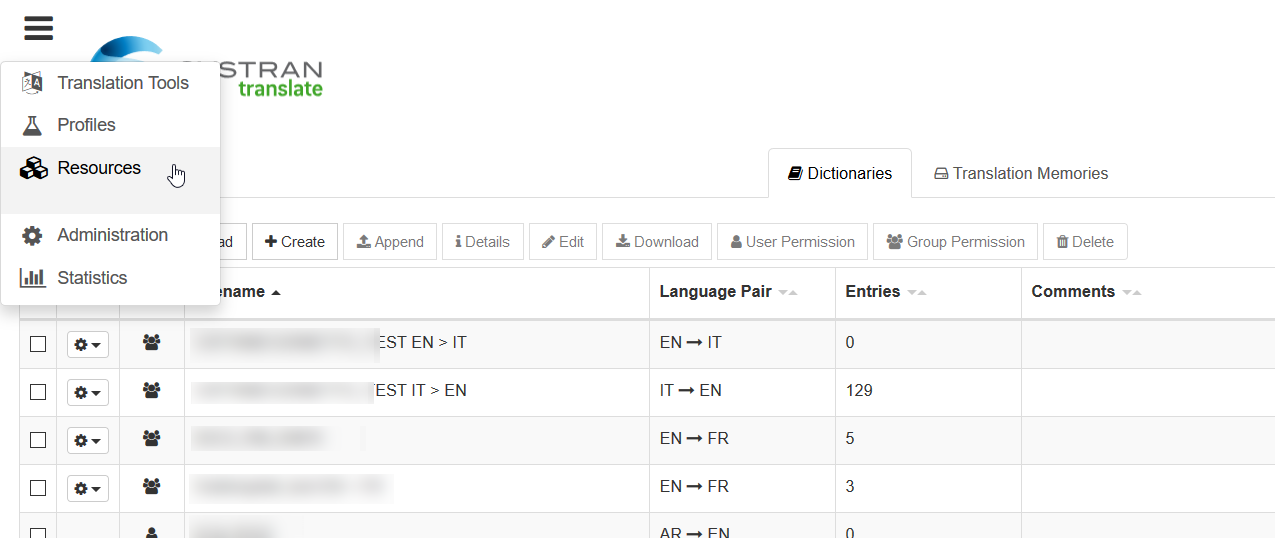
Cela permet aux utilisateurs de mettre en œuvre des ressources linguistiques puissantes adaptées à leurs besoins de traduction. Les utilisateurs peuvent ajouter des mémoires de traduction et des dictionnaires supplémentaires, tels que des dictionnaires de domaine, à un profil afin d’améliorer les traductions.
Une fois les ressources terminées, elles peuvent être ajoutées à un profil via la page Profils.
Note
UD et TM ne peuvent pas être utilisés avec des profils de pivot.
Autorisations
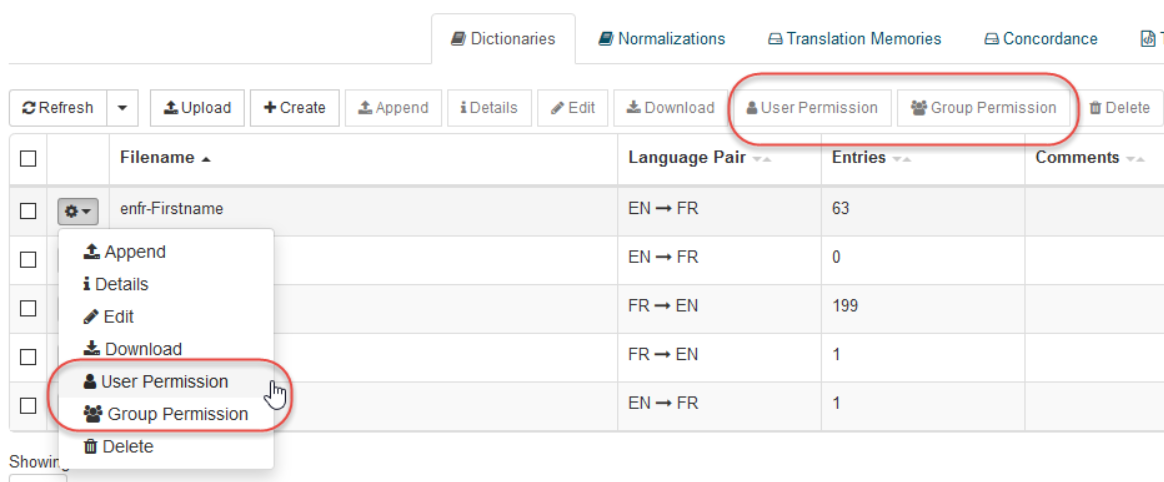
Il est possible de partager avec des utilisateurs donnés, ou avec des groupes, les éléments suivants :
Dictionnaires utilisateur
Mémoires de traduction
Pour chaque élément, cliquez sur le bouton « Autorisation utilisateur » ou « Autorisation de groupe » pour ouvrir la fenêtre contextuelle d’attribution d’autorisation :
Une fois que vous avez ouvert la fenêtre contextuelle d’autorisation, vous pouvez attribuer des autorisations au niveau de l’utilisateur/du groupe en sélectionnant le nom de l’utilisateur ou du groupe. Puis :
Sélectionnez l’autorisation appropriée dans la barre d’outils ou le menu déroulant associé à l’utilisateur/groupe (voir ci-dessous pour plus de détails)
Cliquez sur “Enregistrer” pour l’utilisateur donné
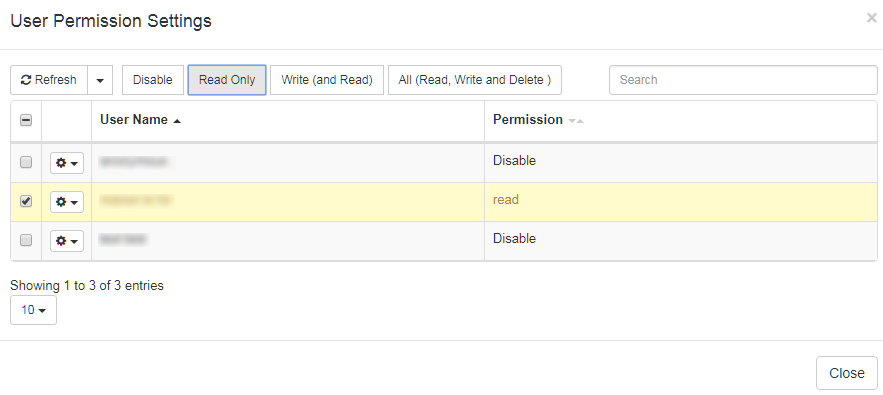
Les utilisateurs ou les groupes peuvent bénéficier des autorisations suivantes :
Désactiver : (par défaut) l’élément n’est pas visible Lecture seule :
l’élément peut être entré en mode lecture seule à partir de la liste (si l’utilisateur a l’autorisation d’accéder à la liste des ressources, par exemple le menu Mémoire de traduction)
l’élément peut être sélectionné par l’utilisateur dans un profil (si l’utilisateur est autorisé à créer des profils)
l’élément sera inclus dans les résultats de recherche dans les outils de « traduction de texte » (c’est-à-dire que les éléments du dictionnaire ou de la mémoire de traduction peuvent apparaître dans la zone Recherche de dictionnaire ou dans les résultats de recherche de la mémoire de traduction)
Write” (et Read) : mêmes droits que ci-dessus, plus
l’utilisateur peut entrer et modifier la ressource
Tous (Lecture, Écriture et Suppression) : mêmes droits que ci-dessus, plus
l’utilisateur peut également supprimer l’élément et définir les autorisations de l’élément pour les autres utilisateurs
Un mécanisme d’autorisation sera également mis en œuvre sur les profils et les profils actifs dans les prochaines versions.
Dictionnaires
Les dictionnaires utilisateur peuvent être affectés à un profil pour améliorer la qualité de vos traductions. La qualité du logiciel de traduction est directement liée au niveau de « compréhension » atteint par le système. Afin d’obtenir un bon niveau de « compréhension », le système doit obtenir non seulement une analyse syntaxique correcte du texte, mais également une analyse sémantique correcte. En effet, certains mots auront des significations et un comportement syntaxique différents selon le contexte sémantique dans lequel ils sont utilisés. Les entrées du dictionnaire utilisateur remplacent les plus d’un million d’entrées intégrées contenues dans les dictionnaires principaux de SYSTRAN au cours du processus de traduction.
Mise à jour des dictionnaires
Vous pouvez effectuer les actions suivantes sur les dictionnaires à partir de la liste Dictionnaires :
Ajouter → Ajouter des entrées en téléchargeant le fichier ; plus de détails ci-dessous
Modifier → Ajouter et modifier des entrées ; plus de détails ci-dessous
Détails → Modifier les propriétés du dictionnaire (nom, langue source et cible) et ajouter ou modifier des commentaires
Télécharger → Télécharger le dictionnaire
Chargement d’un dictionnaire
Pour télécharger des entrées dans le dictionnaire, sélectionnez un dictionnaire, cliquez sur le bouton “Ajouter” puis téléchargez un dictionnaire au format binaire (.dct), Microsoft Excel (.xls) ou texte brut (.txt).
Note
Nous vous recommandons de télécharger un UD ne dépassant pas 200000 segments.
Les dictionnaires créés à l’aide d’une feuille de calcul, telle que Microsoft Excel, ou d’un éditeur de texte commun doivent être mis en forme avec soin avant de pouvoir être importés. Vous trouverez ci-dessous une description détaillée du format requis pour l’importation des dictionnaires.
Fichiers Microsoft Excel
Pour importer des dictionnaires créés avec Microsoft Excel, les fichiers doivent être constitués d’une feuille de calcul pour une traduction, par exemple de l’anglais vers le français. Comme pour les fichiers texte mis en forme, les en-têtes de colonne des fichiers Microsoft Excel pour les colonnes Langues et Informations pour l’UD doivent être entrés en respectant le langage de code ISO 639 à 2 lettres en majuscules.
Fichiers texte mis en forme
Les fichiers texte mis en forme à importer dans SYSTRAN Translate incluent l’en-tête du document et le contenu du dictionnaire. L’en-tête du dictionnaire est une séquence de lignes commençant par le caractère « # » et contenant un champ d’en-tête suivi de sa valeur. Le contenu du dictionnaire est une séquence de lignes, chaque ligne représentant une entrée de dictionnaire dont les champs sont séparés par des tabulations. Les types de champs sont définis dans l’en-tête. Il est important que chaque ligne ait le même nombre de champs, même s’ils sont vides.
Champs obligatoires et facultatifs pour le téléchargement de fichiers dans SYSTRAN Translate :
En-tête |
Description de l’entrée |
|---|---|
#COVERED DOMAINES= |
En-tête facultatif : liste tous les domaines configurés dans le dictionnaire
Note : ne s’applique pas à NMT
|
#ENCODING= |
Obligatoire : définit le codage du fichier. Le codage UTF-8 est recommandé |
#GENERAL DOMAINES DE DICTIONNAIRE= |
En-tête facultatif : liste les domaines système associés au dictionnaire
Note : ne s’applique pas à NMT
|
#SUMMARY= |
Obligatoire : nom du fichier UD |
#MULTI/TM/NORM/DNT #<Langues><Colonnes d’informations>= |
Obligatoire : ces deux lignes constituent la fin de la section d’en-tête. #MULTI définit que le dictionnaire est un dictionnaire utilisateur #TM définit que le dictionnaire est une mémoire de traduction #NORM définit que le dictionnaire est un dictionnaire de normalisation #DNT est utilisé pour séparer dans un dictionnaire utilisateur les entrées multilingues des entrées DNT La deuxième ligne décrit la liste des colonnes de la section de contenu. Il s’agit d’une liste de codes séparés par des tabulations, comme décrit dans le tableau suivant |
Description des différents codes définissant les champs de contenu :
Code |
Description |
|---|---|
XX |
Où XX est un code ISO 639 à 2 lettres en majuscules. Ceci représente une langue (voir l’annexe B. Paires de langues et ISO 639
Codes).La langue source est toujours la première colonne, les langues cibles étant les colonnes suivantes
|
XX_NON |
Pour les dictionnaires de normalisation uniquement. XX correspond au code ISO 639 pour la langue source. Ces colonnes représentent
les colonnes normalisées
|
UPOS |
Partie utilisateur du discours. POS acceptés : acronyme, adjectif, adverbe, conjonction, nom, préposition, nom propre, règle, verbe (orthographié en minuscules).
Ils correspondent au POS dans l’interface, à l’exception de Expression.
|
MOT-CLÉ_XX |
Cette colonne est générée lors d’une exportation. Il contient le mot-clé du champ XX correspondant.
Lors de l’importation, cette colonne est ignorée
|
PRIORITÉ |
Colonne Priorité
Note : ne s’applique pas à NMT
|
DOMAINES |
Colonne Domaines. Les domaines sont séparés par des virgules
Note : ne s’applique pas à NMT
|
FRÉQUENCE |
Colonne de fréquence |
EXEMPLE |
Exemple de colonne |
Exemple de fichier texte formaté :
L’exemple de fichier texte suivant est formaté pour être importé en tant que dictionnaire utilisateur dans SYSTRAN Translate. Notez que <TAB> indique le caractère de tabulation.
#ENCODING=UTF-8
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#COVERED DOMAINS=Computers/Data Processing,Perso
#GENERAL DICTIONARY DOMAINS=Computers/Data Processing
#PRIORITY=1
#SUMMARY=Demo Computer
#MULTI
#EN<TAB>FR<TAB>NOTE<TAB>DOMAINS<TAB>PRIORITY<TAB>UPOS
white cycle<TAB>cycle d'écriture<TAB>Note<TAB>1<TAB>noun
write enable<TAB>validation écriture<TAB><TAB><TAB>noun
#DNT
#EN<TAB>NOTE<TAB>DOMAINS
Print 2000<TAB>It is a DNT<TAB>Perso
L’exemple de fichier texte suivant est formaté pour être importé dans SDM en tant que mémoire de traduction.
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#ENCODING=UTF-8
#SUMMARY=Demo
#TM
#EN<TAB>FR<TAB>DE
My name is Smith<TAB>Mon nom est Smith<TAB>Mein Name ist Smith
Pour utiliser un dictionnaire utilisateur avec un profil :
Cliquez sur Profils
Sélectionner les profils
Développer les options des profils
Dans Ressources, sélectionnez le dictionnaire voulu
Cliquez sur Soumettre
Les entrées des dictionnaires importés peuvent ensuite être modifiées directement sur le serveur en cliquant sur Modifier. Vous trouverez ci-dessous des détails sur l’utilisation de cet outil.
Modification de dictionnaires : tableau de navigation
Cliquez sur Modifier pour accéder à l’outil Éditeur de dictionnaire.
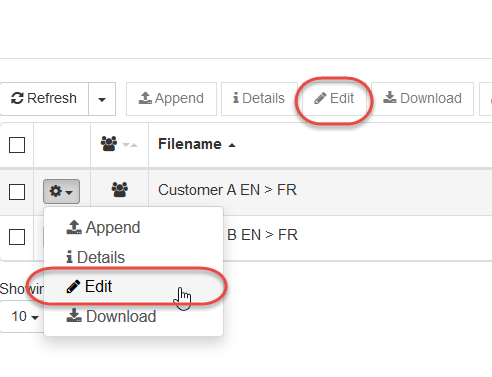
Ceci ouvre une nouvelle page affichant le dictionnaire sous forme de tableau dans lequel les entrées peuvent être affichées, modifiées, ajoutées ou supprimées. Vous pouvez filtrer les entrées de dictionnaire en les triant par ordre alphabétique en fonction des en-têtes de colonne (Source, POS, Cible, Priorité, Commentaires, Confiance). Un filtrage supplémentaire peut être effectué en tapant un mot clé dans la zone de recherche sous l’en-tête de colonne.
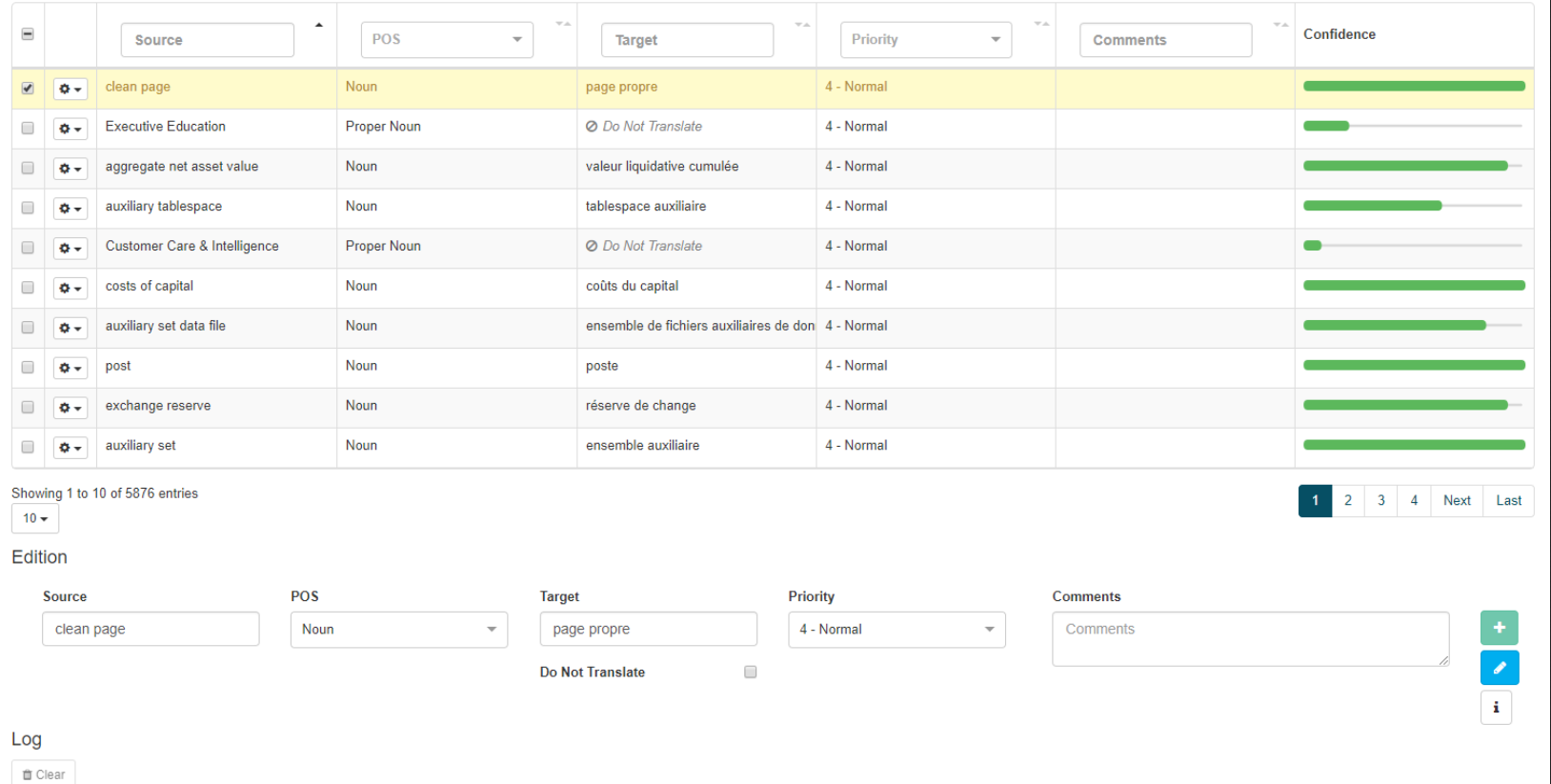
Sur cette page, vous pouvez visualiser les informations suivantes pour chaque entrée de dictionnaire :
Source
Chaque entrée de mot unique ou multiple du dictionnaire est affichée ligne par ligne sous cette colonne. Cliquez sur l’icône Inflexions pour récupérer les informations inflectionnelles de l’entrée
POS
L’entrée source fait partie du discours. Le tableau ci-dessous décrit les parties possibles de la parole :
POS |
Description |
Exemples |
|---|---|---|
Acronyme |
Dans la terminologie SYSTRAN, mot, tout en majuscules, formé à partir des lettres initiales d’autres mots ou parties d’une série de mots |
|
Adjectif |
Mot utilisé pour modifier les noms et pronoms. Inclut les entrées contenant des séquences de plusieurs mots qui doivent être conservées ensemble en tant que bloc et ne seront pas inversées (codées entre guillemets) |
|
Adverbe |
Un mot qui modifie les verbes, les clauses, les adjectifs. Peut être utilisé pour des séquences de plusieurs mots qui doivent être maintenues ensemble comme un bloc et ne seront pas infléchies (codées entre guillemets doubles) |
|
Conjonction |
Mots utilisés comme connecteurs. Note : Nous vous déconseillons fortement d’utiliser ce POS |
|
Expression |
Dans la terminologie SYSTRAN, expression de nom composée de plusieurs noms ou de toute combinaison de noms et d’adjectifs, où le mot-clé est un nom. Les phrases complètes ou les phrases contenant des verbes ne sont pas valides |
|
Nom |
Mot utilisé pour nommer une personne, un lieu, un objet, une qualité ou une action.Utilisez la minuscule si vous voulez faire correspondre tous les cas (inférieur et supérieur) et utilisez des guillemets doubles pour protéger le ou les mots contre les inflexions |
|
Préposition |
Un mot placé avant un nom ou une expression de nom, indiquant la relation de ce nom ou de cette expression de nom avec un verbe, un adjectif ou un autre nom ou expression de nom Note : Nous vous déconseillons fortement d’utiliser ce POS |
|
Nom propre |
Nom appartenant à la classe de mots utilisée pour les personnes, les sociétés, les lieux, etc. L’entrée n’infléchira pas. Utilisez des minuscules pour faire correspondre tous les cas (inférieur et supérieur) |
|
Règle |
Utilisé dans les dictionnaires de normalisation pour correspondre à l’entrée et à ses formes inversées. Utilisé spécialement pour les noms. Par exemple, pour normaliser “exchange” et ses formes infléchies (c’est-à-dire : “exchange”), utilisez la balise POS “rule” |
|
Inconnu |
Balise automatiquement fournie par le moteur de traduction pour les entrées non reconnues qui ne peuvent pas être analysées |
|
Verbe |
Mot qui exprime l’existence, l’action ou l’occurrence. Utilisez l’infinitif. |
|
Cible
Traduction de l’entrée. Cliquez sur l’icône Inflexions pour récupérer les informations inflectionnelles de l’entrée
Priorité
Attribuez une priorité à une entrée allant de 1 (valeur par défaut, recommandée) à 9 (priorité la plus faible). Cela détermine comment l’entrée sera appliquée par rapport aux autres dictionnaires, y compris le dictionnaire principal de SYSTRAN. Pour de plus amples renseignements sur les priorités, veuillez consulter le tableau ci-dessous :
Priorité |
Description |
|---|---|
1 |
Les entrées de priorité 1 ont priorité sur toute autre règle de codage de dictionnaire. Utilisez cette priorité avec précaution, car elle peut dégrader la traduction principale en masquant des termes grammaticaux, des expressions communes ou des homographies communes |
2 |
Les entrées de priorité 2 ont la priorité sur les expressions plus longues des dictionnaires intégrés SYSTRAN, mais pas sur les termes/règles grammaticaux (ceux qui sont exclus uniquement par la priorité 1) |
3 |
Les entrées de priorité 3 n’ont pas priorité sur les expressions plus longues ou les règles grammaticales, et les homographies des dictionnaires intégrés SYSTRAN ne sont pas prises en compte. Pour deux entrées de priorité 3, c’est l’ordre du dictionnaire qui décide. Notez que les expressions plus longues avec une priorité inférieure (4-7) ont priorité sur une entrée de priorité 3 |
4 - 6 |
Les entrées prioritaires 4 à 6 n’ont pas priorité sur les expressions plus longues ou les règles grammaticales et les homographies des dictionnaires intégrés SYSTRAN sont conservées. L’ordre d’utilisation est défini par l’ordre du dictionnaire défini dans les options de traduction |
7 |
Les entrées de priorité 7 ne doivent être utilisées que si aucune autre entrée ne correspond à partir d’autres dictionnaires. Cette priorité aura uniquement un impact sur les mots introuvables |
8 |
Les entrées de la priorité 8 ne doivent jamais avoir la priorité, mais s’afficheront dans d’autres sens |
9 |
Les entrées de la priorité 9 ne doivent jamais être utilisées et ne s’afficheront pas dans d’autres sens. Utilisez cette priorité pour désactiver une entrée sans la supprimer. Les utilisateurs peuvent également appliquer cette priorité lors de l’utilisation de l’opérateur de recherche Rechercher s’ils ne veulent pas qu’un sous-dictionnaire référencé dans l’opérateur corresponde |
Commentaires
Ajouter des commentaires relatifs à l’entrée (par exemple : date ajoutée, auteur de l’entrée ajoutée, etc.)
Fiabilité
Indique la qualité de codage de l’entrée, c’est-à-dire à quel point la traduction correspond à la source. Cette mesure est le résultat d’une comparaison avec la base de données de ressources linguistiques SYSTRAN. Plus la barre est haute, plus la confiance est forte
Supprimer
Supprimer la ligne contenant l’entrée
Modification de dictionnaires : Modification d’une zone
Sous la table de navigation se trouve une autre table (Edition & Log) où les entrées existantes peuvent être modifiées et les nouvelles entrées ajoutées au dictionnaire.
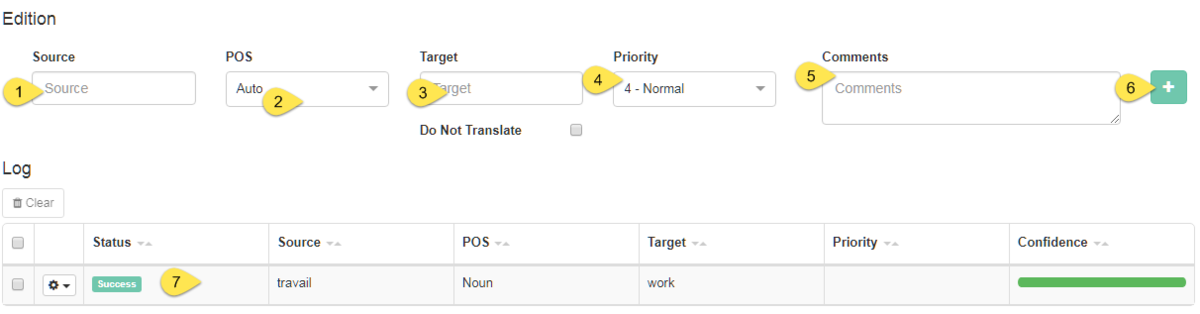
Pour modifier une entrée existante, cliquez sur sa ligne dans le tableau Éditeur de dictionnaire pour la mettre en surbrillance. Il apparaîtra dans les champs en bas de la page. Si aucune entrée n’est mise en surbrillance, ces champs seront vides et une nouvelle entrée pourra être ajoutée en remplissant le :
Source
POS
Cible
Priorité
Commentaires
Cliquez sur Ajouter (ou sur Modifier en cas de modification d’une entrée existante)
Lorsqu’une entrée est ajoutée avec succès, son état s’affiche comme Codage réussi. Si ce n’est pas le cas, contactez votre administrateur. Lors de l’ajout d’une nouvelle entrée, sa confiance sera également calculée et affichée
Lors de la détermination du POS, utilisez le lemme de l’entrée, sauf s’il s’agit d’une expression ou d’une règle. Par défaut, l’affectation d’un PDV est effectuée automatiquement. Si l’entrée est un nom propre qui ne doit pas être traduit, cochez la case Ne pas traduire. Placez le curseur sur l’icône d’informations en bas à droite de la page pour apprendre à utiliser les raccourcis clavier.
Téléchargement de dictionnaires
Cliquez sur Télécharger
Renommez le fichier téléchargé avec l’extension “.txt” pour ouvrir le fichier
Codage de dictionnaire
Caractères spéciaux
impossible d’utiliser le hachage #
certains caractères doivent être protégés :
les guillemets « « « et les parenthèses « ()« doivent être précédés d’une barre oblique inverse « « afin qu’ils soient considérés comme faisant partie de l’entrée et non de la syntaxe de codage ; ils apparaîtront dans l’entrée codée (sans la barre oblique inverse)
la barre oblique inverse «» doit être entrée en tant que «\» ; elle s’affichera en tant que «\» dans l’entrée codée
notez que la plupart des tirets (en tiret « - », en tiret « —«etc.) seront normalisés en tiret moins « -« dans l’entrée de traduction (donc si l’entrée de dictionnaire contient un tiret en tiret, il ne correspondra pas à l’entrée normalisée)
la plupart des guillemets seront normalisés en guillemets droits dans l’entrée de traduction, et les guillemets droits peuvent être normalisés en d’autres guillemets (locaux) dans la sortie
Indices de codage
les guillemets « « « peuvent être utilisés pour figer (une partie de) l’entrée afin qu’elle ne s’influe pas ; les guillemets ne s’afficheront pas dans l’entrée codée
des indices de codage entre parenthèses pour le nombre (sg, pl), le sexe (m, f, neutre) et d’autres informations morpho-syntaxiques peuvent être utilisés pour certaines langues
Normalisations
Les dictionnaires de normalisation (ND) sont un moyen de réguler le texte avant et après la traduction. Ils permettent de normaliser la terminologie et d’étendre les abréviations et les acronymes. Les ND peuvent également servir à normaliser l’orthographe et à établir une terminologie commune (p. ex., les cas où deux mots ou plus sont utilisés pour le même concept).
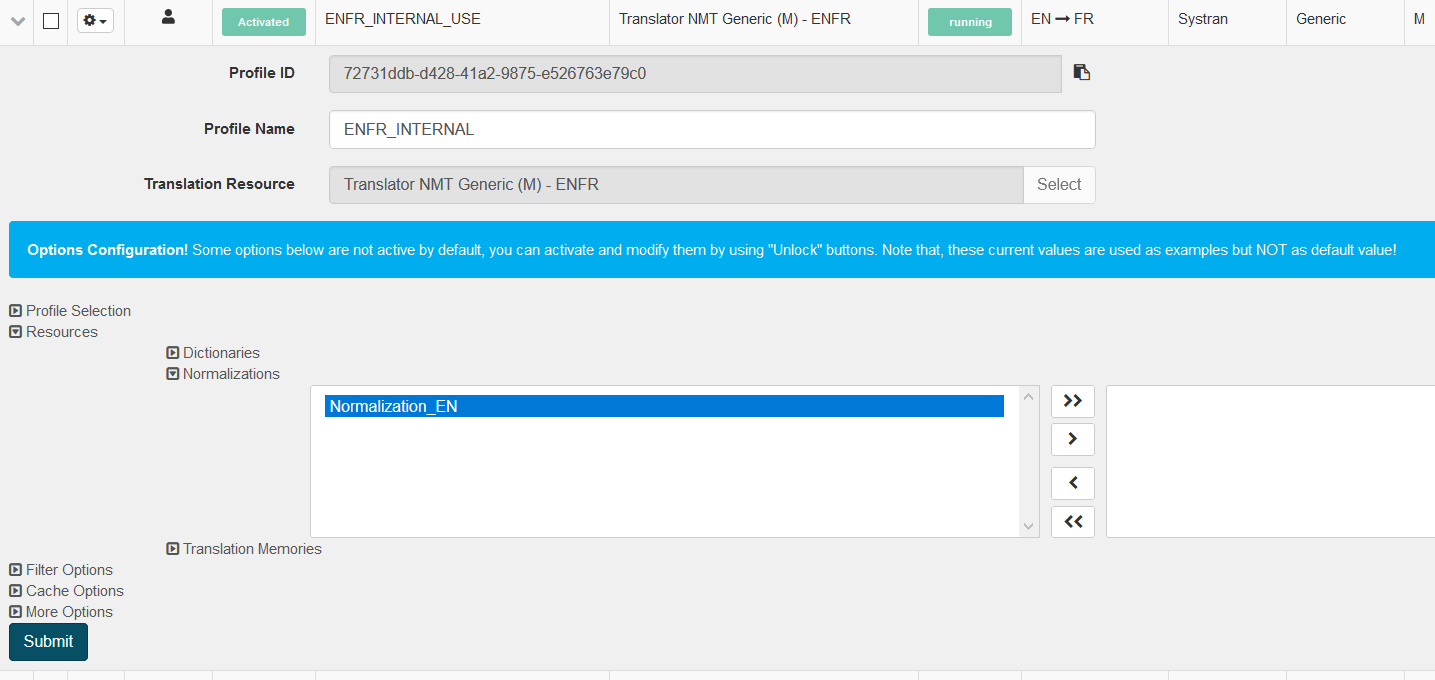
Vous pouvez ajouter vos dictionnaires de normalisation (pour la langue source ou pour la langue cible) à un profil. Si un dictionnaire de normalisation est indiqué pour la langue source, il traitera le texte d’entrée source avant la traduction. Si le dictionnaire de normalisation est destiné à la langue cible, il traite le texte traduit.
Pour créer un dictionnaire de normalisation, dans Ressources, cliquez sur Normalisations puis sur Créer pour ouvrir une boîte de dialogue :
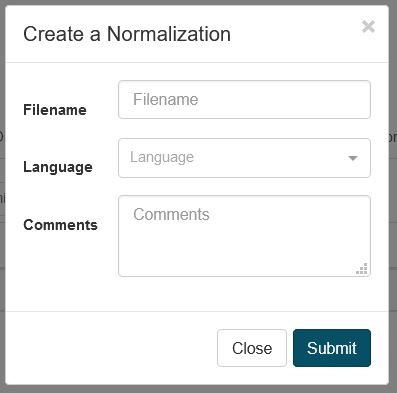
Choisissez un nom pour votre dictionnaire de normalisation et sélectionnez la langue
Cliquez sur Soumettre pour créer le dictionnaire de normalisation
Les mêmes directives s’appliquent au téléchargement, au téléchargement et à la modification d’un dictionnaire de normalisation qu’un dictionnaire utilisateur. Reportez-vous à la section Dictionnaires ci-dessus.
Lors de l’importation d’un nouveau dictionnaire de normalisation, assurez-vous que le format de l’en-tête est correct. L’exemple de fichier texte suivant est formaté pour importer un dictionnaire de normalisation dans SYSTRAN Translate. Notez que <TAB> indique le caractère de tabulation.
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#SUMMARY=EN NORMALIZATION DICTIONARY
#ENCODING=UTF-8
#COVERED DOMAINS=coll
#GENERAL DICTIONARY DOMAINS=coll
#NORM
#EN EN_NO UPOS DOMAINS NOTE
youre <TAB> you are <TAB> sequence
4ever <TAB> forever <TAB> sequence
Une fois que vous avez créé ou importé un dictionnaire de normalisation, vous pouvez l’associer à un profil.
Mémoires de traduction
Les mémoires de traduction (TM) sont utiles pour établir la cohérence de traduction dans un ensemble de fichiers documentés. Les mémoires de traduction sont des ensembles de paires de phrases comprenant chacune une phrase source et sa traduction, stockées dans une base de données bilingue ou multilingue. L’utilisation d’une mémoire de traduction permet d’extraire des mots ou des expressions de textes déjà traduits au cours du processus de traduction. Contrairement aux entrées du dictionnaire utilisateur, qui restent sujettes à l’analyse linguistique, les traductions de phrases qui existent dans les TM sont statiques. Lors de la traduction d’un document avec un Profil contenant des TM, les phrases présentes dans la mémoire (correspondances exactes) remplaceront la traduction automatique. Plutôt que de retraduire cette phrase, SYSTRAN place simplement la phrase cible correspondante déjà traduite dans le document.
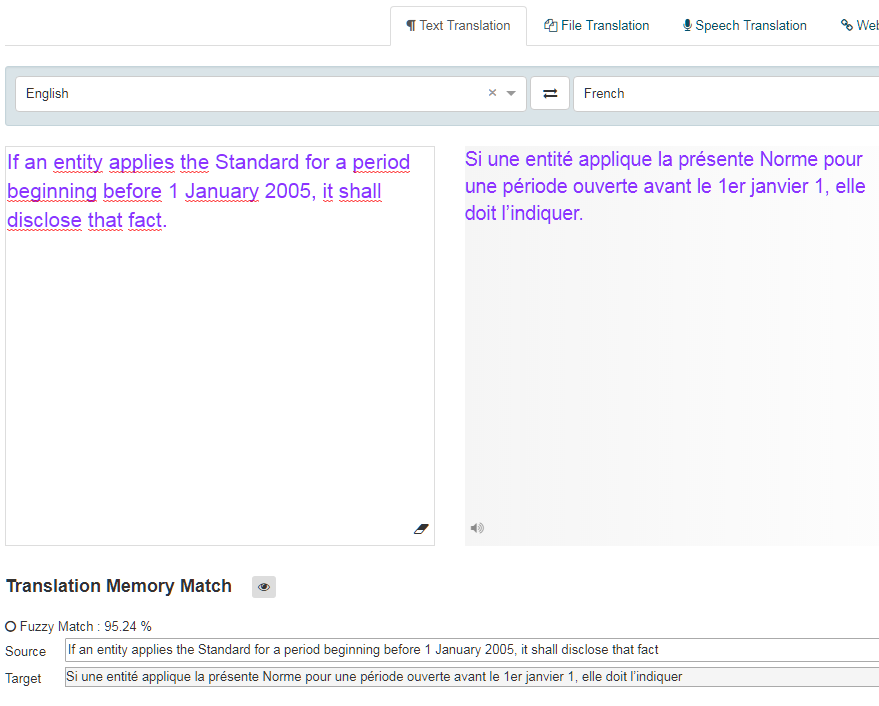
Lors d’une traduction avec une mémoire de traduction, un segment du texte source qui correspond exactement à un segment de la base de données de la mémoire de traduction correspond exactement à un score de 1,0 (100 %) et un segment qui correspond partiellement correspond à une correspondance floue avec une valeur inférieure à 1 (<100 %). Le score compare l’entrée avec la correspondance de la mémoire de traduction et calcule les similarités entre les deux. Plus le score est élevé, plus le match est serré. La base de données renvoie toutes les correspondances supérieures au seuil de correspondance floue configuré par l’administrateur (70 % par défaut). Ces correspondances seront affichées sous la forme de correspondances approximatives dans l’outil de traduction de texte et dans l’éditeur de traduction lors de la révision d’une traduction de fichier.
Dans la zone Traduction de texte, la correspondance floue est mise en surbrillance en vert et le score est affiché.
En outre, les mémoires de traduction peuvent être utilisées comme corpus de test, de réglage ou de formation dans vos projets de formation en traduction.
Création d’une mémoire de traduction
Créer des mémoires de traduction
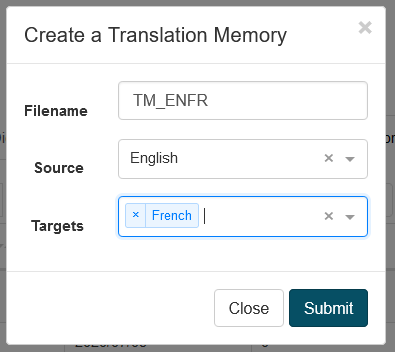
Pour créer une mémoire de traduction, cliquez sur le bouton Créer, puis vous devrez enregistrer le nom de fichier TM, une langue source et une langue cible.
Téléchargement d’une mémoire de traduction
Les fichiers TMX (Translation Memory eXchange) sont une spécification de XML. SYSTRAN Translate prend en charge les versions TMX comprises entre 1.2 et 1.4. Pour plus d’informations, voir la page TMX de la Localization Industry Standards Association <https://www.gala-global.org/lisa-oscar-standards/>`_.
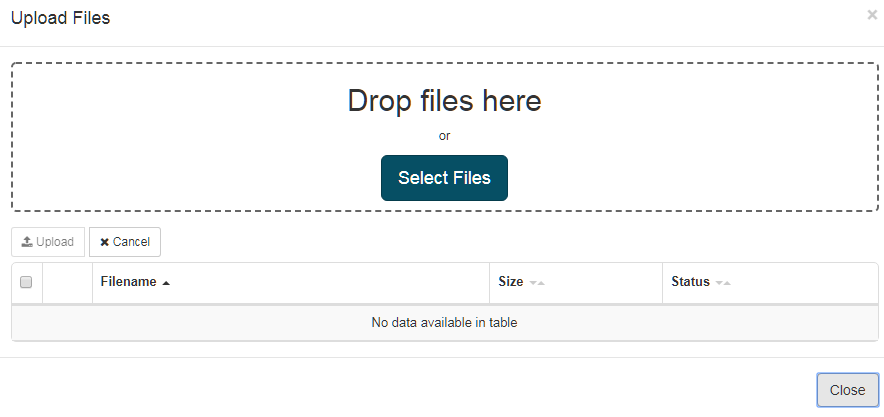
Pour télécharger une mémoire de traduction, cliquez sur Ressources puis Mémoire de traduction, sélectionnez la mémoire de traduction souhaitée et cliquez sur Modifier. Cliquez sur « Ajouter » Une boîte de dialogue apparaîtra :
Une fois téléchargées, les entrées de la mémoire de traduction apparaissent sur la page Mémoire de traduction.
Note
Nous vous recommandons de télécharger une TM ne dépassant pas 200000 segments.
Pour utiliser une mémoire de traduction avec un profil :
Cliquez sur Profils
Sélectionner les profils
Développer les options des profils
Dans Ressources, sélectionnez la mémoire de traduction souhaitée
Cliquez sur Soumettre
Éditeur de mémoires de traduction
Accédez à Ressources > Mémoires de traduction
Cliquez sur Modifier
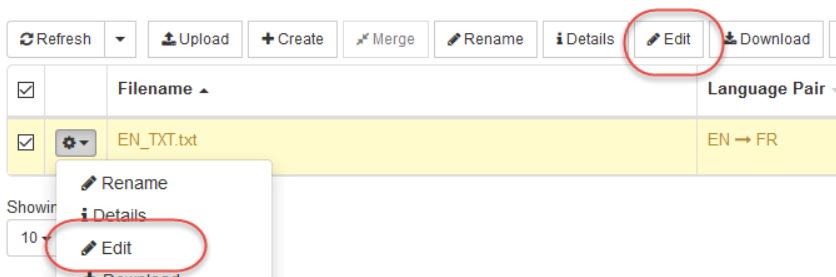
L’éditeur de mémoire de traduction s’ouvre
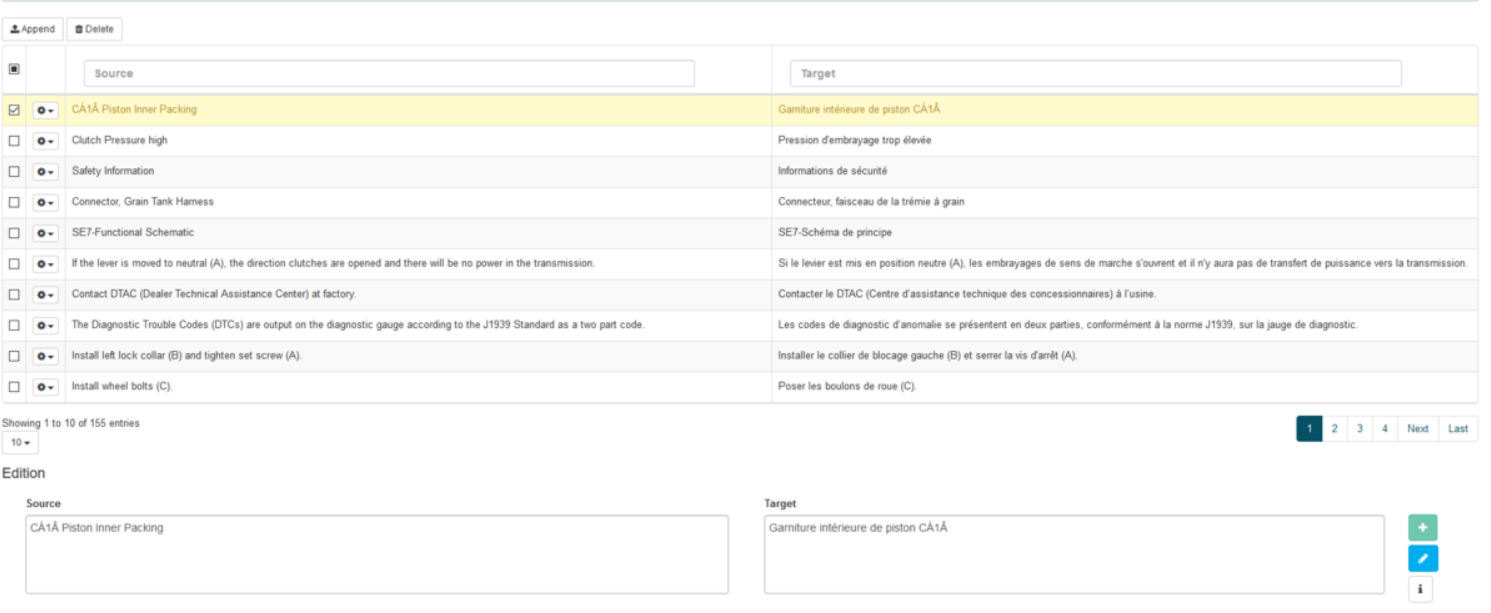
Modifier une phrase
Sélectionner l’entrée
Mettre à jour les champs requis (source et/ou cible)
Cliquez sur le bouton « Modifier » ou appuyez sur la touche Entrée du clavier
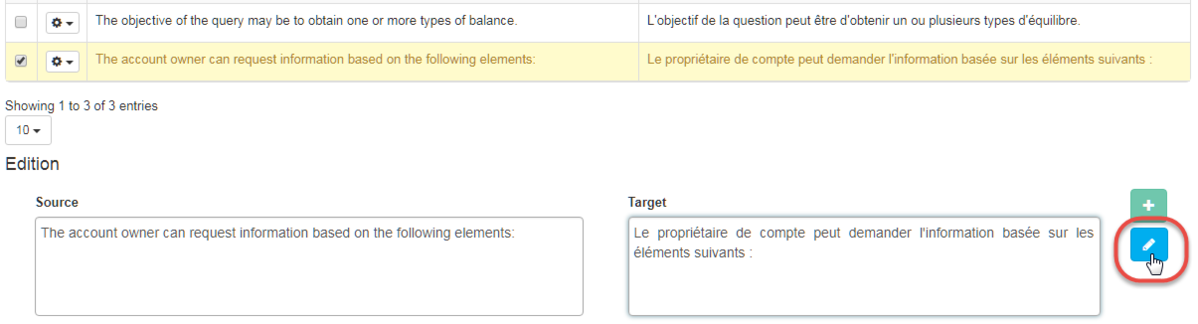
Ajouter un nouveau segment dans la mémoire de traduction
Vous pouvez ajouter directement une entrée via les champs source et cible :


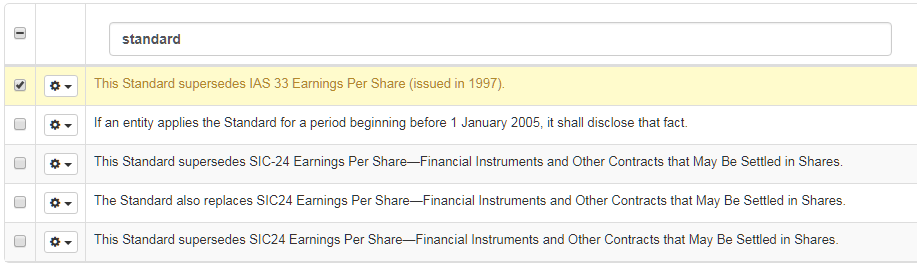
Rechercher une phrase
Pour rechercher des phrases spécifiques, saisissez le mot ou la phrase que vous recherchez dans le champ Segment source ou cible :
Supprimer un segment
Sélectionner un segment
Cliquez sur Supprimer
Cliquez sur Soumettre pour confirmer la suppression