Gestión de recursos
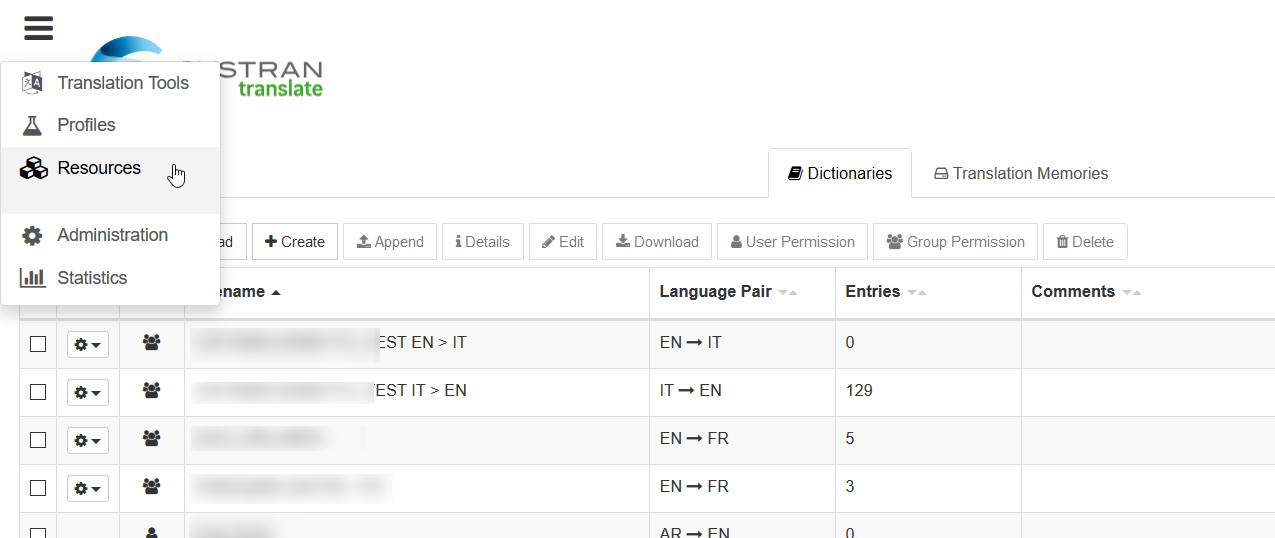
En SYSTRAN Translate se pueden gestionar diversos recursos lingüísticos a través del menú Resources.
Esto permite a los usuarios implementar potentes recursos lingüísticos que se adaptan a sus necesidades de traducción. Los usuarios pueden agregar memorias de traducción y diccionarios adicionales como Diccionarios de dominio a un perfil para mejorar las traducciones.
Una vez completados los recursos, se pueden agregar a un perfil a través de la página Perfiles.
Nota
UD y TM no se pueden utilizar con perfiles de pivote.
Permisos
Es posible compartir con determinados usuarios, o con grupos, los siguientes elementos:
Diccionarios de usuario
Memorias de traducción
Para cada elemento, haga clic en el botón ‘Permiso de usuario’ o ‘Permiso de grupo’ para abrir el pop-up de asignación de permisos:
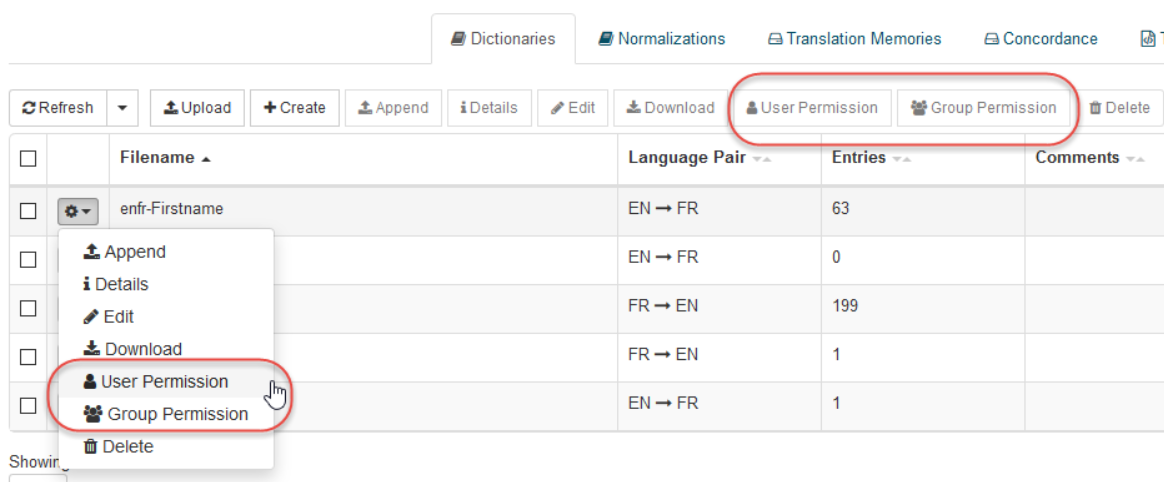
Una vez abierto el elemento emergente de permisos, puede asignar permisos en el nivel de usuario/grupo seleccionando el nombre del usuario o grupo. A continuación:
Seleccione el permiso adecuado en la barra de herramientas o el menú desplegable asociado al usuario/grupo (consulte a continuación para obtener más detalles)
Haga clic en “Guardar” para el usuario dado
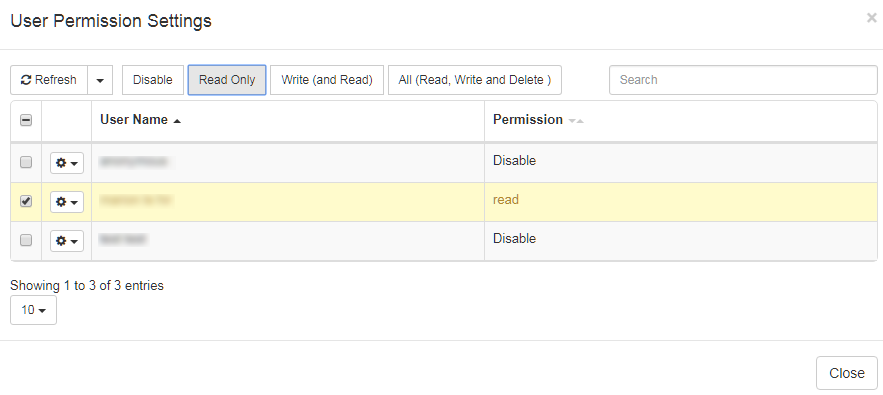
A los usuarios o grupos se les pueden conceder los permisos siguientes:
Deshabilitar: (de forma predeterminada) el elemento no está visible Sólo lectura:
el elemento se puede introducir en modo de sólo lectura desde la lista (si el usuario tiene permiso para acceder a la lista de recursos, por ejemplo, el menú Memoria de traducción)
el usuario puede seleccionar el elemento en un perfil (si el usuario tiene permiso para crear perfiles)
el elemento se incluirá en los resultados de la búsqueda en las herramientas de “Traducción de texto” (es decir, los elementos del diccionario o de la memoria de traducción pueden aparecer en el cuadro de búsqueda del diccionario o en los resultados de la búsqueda de la memoria de traducción)
Escritura” (y lectura): los mismos derechos que los anteriores, más
el usuario puede introducir y modificar el recurso
Todos (lectura, escritura y eliminación): los mismos derechos que los anteriores, más
el usuario también puede eliminar el elemento y establecer los permisos del elemento para otros usuarios
También se implementará un mecanismo de permisos en los perfiles y perfiles activos en las próximas versiones.
Diccionarios
Los diccionarios de usuario se pueden asignar a un perfil para mejorar la calidad de sus traducciones. La calidad del software de traducción está directamente relacionada con el nivel de “comprensión” alcanzado por el sistema. Para obtener un buen nivel de “comprensión”, el sistema debe obtener no sólo un análisis sintáctico correcto del texto, sino también un análisis semántico correcto. Esto se debe a que algunas palabras tendrán diferentes significados y comportamiento sintáctico dependiendo del contexto semántico en el que se utilizan. Las entradas del diccionario del usuario sustituyen a las más de un millón de entradas incorporadas en los principales diccionarios de SYSTRAN durante el proceso de traducción.
Actualizar diccionarios
Puede realizar las siguientes acciones en los diccionarios de la lista Diccionarios:
Append → Añadir entradas por archivo de carga; más detalles a continuación
Editar → Añadir y editar entradas; más detalles a continuación
Detalles → Modifique las propiedades del diccionario (nombre, idioma de origen y destino) y agregue o edite comentarios
Descargar → Descargar el diccionario
Cargar un diccionario
Para cargar entradas en el diccionario, seleccione un diccionario, haga clic en el botón “Anexar” y cargue un diccionario en formato binario (.dct), Microsoft Excel (.xls) o texto sin formato (.txt).
Nota
Se recomienda cargar un DU que no supere los 200000 segmentos.
Los diccionarios creados con una aplicación de hoja de cálculo, como Microsoft Excel, o un editor de texto común deben tener un formato cuidadoso antes de poder importarse. A continuación se incluye una descripción detallada del formato necesario para importar diccionarios.
Archivos de Microsoft Excel
Para importar diccionarios creados con Microsoft Excel, los archivos deben constar de una hoja de cálculo para una traducción, por ejemplo, del inglés al francés. Al igual que en el caso de los archivos de texto con formato, los encabezados de columna de los archivos de Microsoft Excel para los idiomas y las columnas de información para el identificador de usuario deben introducirse respetando el lenguaje de código ISO 639 de 2 letras en mayúsculas.
Archivos de texto con formato
Los archivos de texto con formato para importar en SYSTRAN Translate incluyen el encabezado del documento y el contenido del diccionario. El encabezado del diccionario es una secuencia de líneas que comienza con el carácter “#” y contiene un campo de encabezado seguido de su valor. El contenido del diccionario es una secuencia de líneas, cada una de las cuales representa una entrada del diccionario cuyos campos están separados por tabuladores. Los tipos de campo se definen en el encabezado. Es importante que cada línea tenga el mismo número de campos, incluso si están vacíos.
Campos obligatorios y opcionales para cargar archivos en SYSTRAN Translate:
Encabezado |
Descripción de la entrada |
|---|---|
#DOMINIOS CUBIERTOS= |
Cabecera opcional: muestra todos los dominios configurados en el diccionario
Nota: no aplicable a NMT
|
#CODIFICACIÓN= |
Requerido: define la codificación del archivo. Se recomienda la codificación UTF-8 |
#DOMINIOS DEL DICCIONARIO GENERAL= |
Cabecera opcional: muestra los dominios del sistema asociados al diccionario
Nota: no aplicable a NMT
|
#RESUMEN= |
Requerido: el nombre del archivo UD |
#MULTI/TM/NORM/DNT #<Idiomas><Columnas informativas>= |
Requerido: Estas dos líneas son el final de la sección de cabecera. #MULTI define que el diccionario es un diccionario de usuario #TM define que el diccionario es una memoria de traducción #NORM define que el diccionario es un diccionario de normalización #DNT se utiliza para separar en un diccionario de usuario las entradas multilingües de las entradas DNT La segunda línea describe la lista de columnas de la sección de contenido. Es una lista de códigos separados por caracteres de tabulación como se describe en la tabla siguiente |
Descripción de los diferentes códigos que definen los campos de contenido:
Código |
Descripción |
|---|---|
XX |
Donde XX es un código ISO 639 de 2 letras en mayúsculas. Representa un idioma (consulte el Apéndice B. Pares de idiomas e ISO 639
Codes).El idioma de origen es siempre la primera columna, con los idiomas de destino como las siguientes columnas
|
XX_NO |
Sólo para diccionarios de normalización. XX corresponde al código ISO 639 para el idioma de origen. Estas columnas representan
las columnas normalizadas
|
UPOS |
Parte de usuario de la voz. POS aceptado: acrónimo, adjetivo, adverbio, conjunción, sustantivo, preposición, sustantivo, regla, verbo (escrito en minúsculas).
Corresponden al POS en la interfaz, excepto por Expression.
|
ENCABEZADO XX |
Esta columna se genera al realizar una exportación. Contiene el encabezamiento del campo XX correspondiente.
Durante la importación, esta columna se omite
|
PRIORIDAD |
Columna Prioridad
Nota: no aplicable a NMT
|
DOMINIOS |
Columna Dominios. Los dominios están separados por comas
Nota: no aplicable a NMT
|
FRECUENCIA |
Columna Frecuencia |
EJEMPLO |
Columna de ejemplo |
Archivo de texto con formato de ejemplo:
El siguiente archivo de texto de ejemplo tiene formato para importarlo como diccionario del usuario en SYSTRAN Translate. Observe que <TAB> indica el carácter de tabulación.
#ENCODING=UTF-8
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#COVERED DOMAINS=Computers/Data Processing,Perso
#GENERAL DICTIONARY DOMAINS=Computers/Data Processing
#PRIORITY=1
#SUMMARY=Demo Computer
#MULTI
#EN<TAB>FR<TAB>NOTE<TAB>DOMAINS<TAB>PRIORITY<TAB>UPOS
white cycle<TAB>cycle d'écriture<TAB>Note<TAB>1<TAB>noun
write enable<TAB>validation écriture<TAB><TAB><TAB>noun
#DNT
#EN<TAB>NOTE<TAB>DOMAINS
Print 2000<TAB>It is a DNT<TAB>Perso
El siguiente archivo de texto de ejemplo tiene formato para importarlo en SDM como memoria de traducción.
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#ENCODING=UTF-8
#SUMMARY=Demo
#TM
#EN<TAB>FR<TAB>DE
My name is Smith<TAB>Mon nom est Smith<TAB>Mein Name ist Smith
Para utilizar un diccionario de usuario con un perfil:
Haga clic en Perfiles
Seleccione los perfiles
Expandir las opciones de perfiles
En Recursos, seleccione el diccionario deseado
Haga clic en Enviar
Las entradas de diccionarios importados se pueden modificar directamente en el servidor haciendo clic en Editar. A continuación encontrará información sobre cómo utilizar esta herramienta.
Edición de diccionarios: tabla de navegación
Haga clic en Editar para acceder a la herramienta Editor de diccionarios.
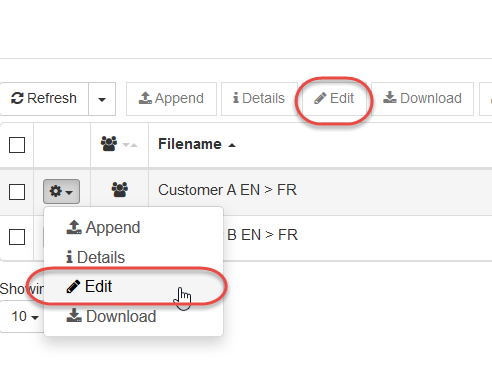
Esto abre una nueva página que muestra el diccionario en formato de tabla en la que las entradas se pueden ver, modificar, agregar o eliminar. Puede filtrar las entradas del diccionario ordenándolas alfabéticamente en función de los encabezados de columna (Origen, POS, Destino, Prioridad, Comentarios, Confianza). Se puede realizar un filtrado adicional escribiendo una palabra clave en el cuadro de búsqueda situado debajo del encabezado de la columna.
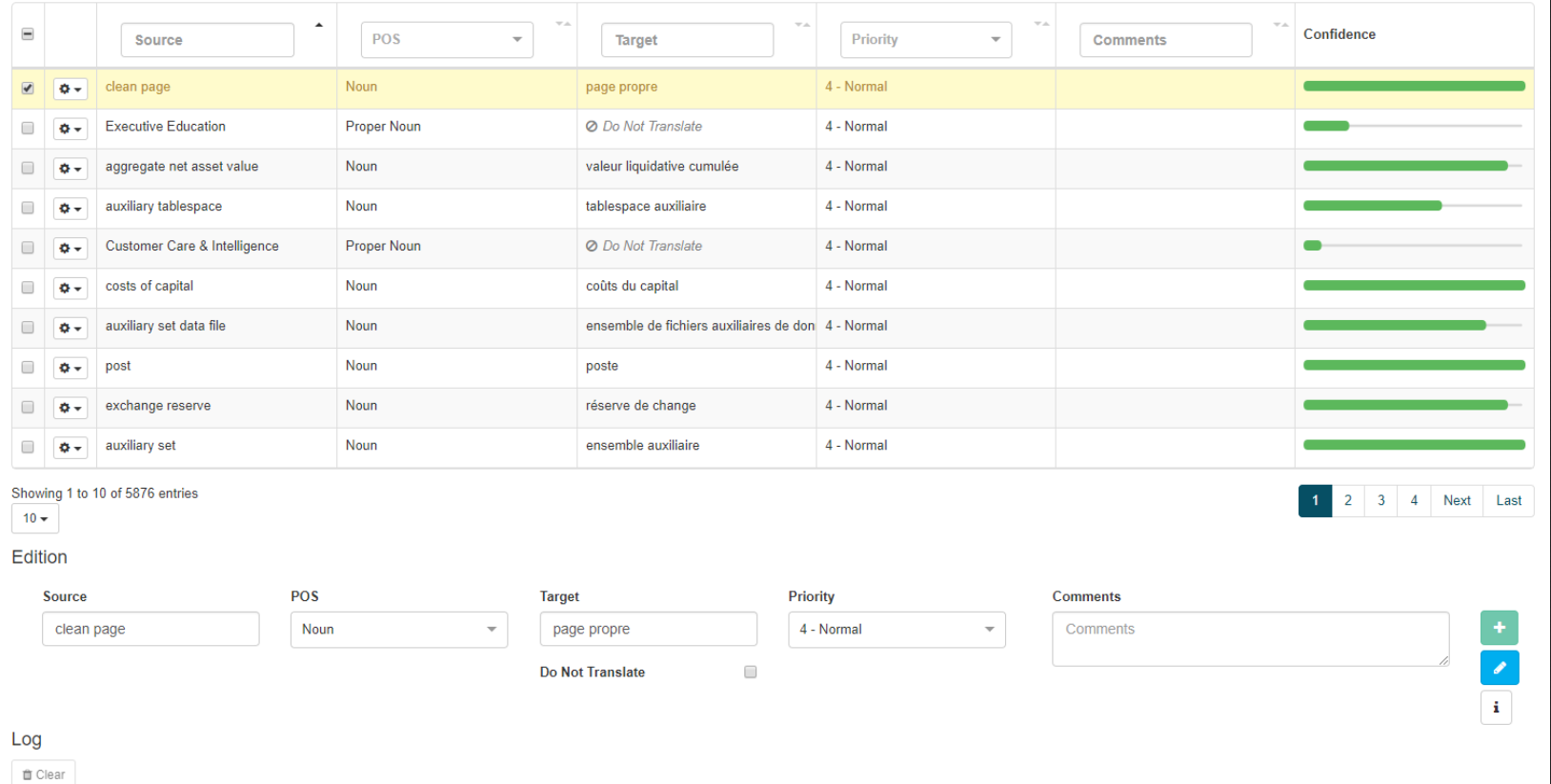
En esta página puede ver la siguiente información para cada entrada de diccionario:
Fuente
Cada entrada de una o varias palabras del diccionario se muestra fila por fila debajo de esta columna. Haga clic en el icono Inflections para recuperar la información inflectiva de la entrada
POS
La entrada de origen es parte de la voz. En la tabla siguiente se describen las posibles partes del habla:
POS |
Descripción |
Ejemplos |
|---|---|---|
Acrónimo |
En la terminología SYSTRAN, una palabra, todas en mayúsculas, formada a partir de las letras iniciales de otras palabras o partes de una serie de palabras |
|
Adjetivo |
Palabra utilizada para modificar sustantivos y pronombres. Incluye entradas que contienen secuencias de varias palabras que se deben mantener juntas como un bloque y no se infectarán (codificadas entre comillas dobles) |
|
Adverbio |
Palabra que modifica verbos, cláusulas y adjetivos. Se puede utilizar para secuencias de varias palabras que deben mantenerse juntas como un bloque y no se inflexionarán (codificadas entre comillas dobles) |
|
Conjunción |
Palabras utilizadas como conectores. Nota: Recomendamos encarecidamente no usar este POS |
|
Expresión |
En la terminología SYSTRAN, un sustantivo que consiste en más de un sustantivo o cualquier combinación de sustantivos y adjetivos, donde el encabezamiento es un sustantivo. Las oraciones completas o las frases que contienen verbos no son válidas |
|
Sustantivo |
Palabra que se utiliza para nombrar a una persona, un lugar, una cosa, una calidad o una acción.Utilice minúsculas si desea que coincidan todas las mayúsculas y minúsculas (inferior y superior) y utilice comillas dobles para evitar que las palabras se infecten |
|
Preposición |
Una palabra colocada antes de un sustantivo o frase sustantivo, que indica la relación de ese sustantivo o frase sustantivo con un verbo, un adjetivo u otro sustantivo o frase sustantivo Nota: Recomendamos encarecidamente no usar este POS |
|
Nombre propio |
Nombre perteneciente a la clase de palabras utilizadas para personas, empresas, lugares, etc. La entrada no influirá. Utilice minúsculas si desea que coincidan todas las mayúsculas y minúsculas (inferior y superior) |
|
Regla |
Se utiliza en los diccionarios de normalización para hacer coincidir la entrada y sus formas inflexionadas. Se usa especialmente para los sustantivos. Por ejemplo, para normalizar “exchange” y sus formas infladas (por ejemplo: “exchange”), use la etiqueta POS “rule” |
|
Desconocido |
Etiqueta proporcionada automáticamente por el motor de traducción para entradas no reconocidas que no se pueden analizar |
|
Verbo |
Palabra que expresa existencia, acción u ocurrencia. Usa infinitivo. |
|
Objetivo
La traducción de la entrada. Haga clic en el icono Inflections para recuperar la información inflectiva de la entrada
Prioridad
Asigne una prioridad a una entrada comprendida entre 1 (predeterminado, recomendado) y 9 (prioridad más baja). Esto determina cómo se aplicará la entrada en relación con otros diccionarios, incluido el diccionario principal de SYSTRAN. Para obtener más información sobre las prioridades, consulte la tabla siguiente:
Prioridad |
Descripción |
|---|---|
1 |
Las entradas de prioridad 1 tienen prioridad sobre cualquier otra regla de codificación de diccionario. Utilice esta prioridad con cuidado, ya que puede degradar la traducción principal ocultando términos gramaticales, expresiones comunes u homógrafos comunes |
2 |
Las entradas de prioridad 2 tienen precedencia sobre las expresiones más largas de los diccionarios integrados SYSTRAN, pero no sobre los términos/reglas gramaticales (los que solo se excluyen por prioridad 1) |
3 |
Las entradas de prioridad 3 no tienen prioridad sobre expresiones más largas o reglas gramaticales, y no se consideran los homógrafos de los diccionarios integrados SYSTRAN. Para dos entradas con prioridad 3, el orden del diccionario decide. Tenga en cuenta que las expresiones más largas con menor prioridad (4-7) tienen prioridad sobre una entrada de prioridad 3 |
4 - 6 |
Las entradas de prioridad 4 - 6 no tienen prioridad sobre expresiones más largas o reglas gramaticales y se conservan los homógrafos de los diccionarios integrados SYSTRAN. El orden de uso se define mediante el orden de diccionario establecido en Opciones de traducción |
7 |
Las entradas de prioridad 7 sólo se deben utilizar si no hay otras entradas que coincidan con las de otros diccionarios. Esta prioridad sólo afectará a Palabras no encontradas |
8 |
Las entradas de prioridad 8 nunca deben tener prioridad, pero se mostrarán con significados alternativos |
9 |
Las entradas de prioridad 9 nunca deben utilizarse y no se mostrarán en significados alternativos. Utilice esta prioridad para deshabilitar una entrada sin quitarla. Los usuarios también pueden aplicar esta prioridad al utilizar el operador Buscar si no desean que coincida un subdiccionario al que se hace referencia en el operador |
Comentarios
Agregar comentarios pertenecientes a la entrada (por ejemplo: fecha de adición, autor de entrada agregada, etc.)
Confianza
Indica la calidad de codificación de la entrada, es decir, la medida en que la traducción se corresponde con el origen. Esta medida es el resultado de una comparación con la base de datos de recursos lingüísticos SYSTRAN. Cuanto más lleno esté el listón, más fuerte será la confianza
Suprimir
Eliminar la línea que contiene la entrada
Editar diccionarios: Zona de edición
Debajo de la tabla de navegación hay otra tabla (Edición y Registro) en la que se pueden modificar las entradas existentes y añadir nuevas entradas al diccionario.
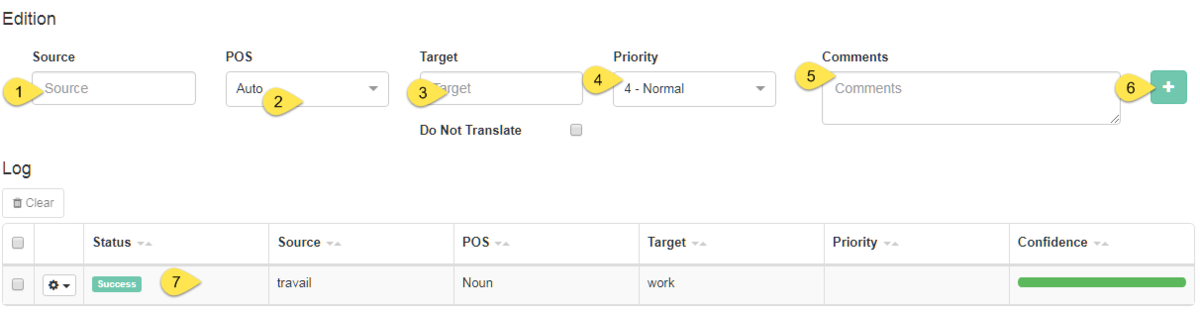
Para modificar una entrada existente, haga clic en la fila de la entrada en la tabla Editor de diccionarios para resaltarla. Aparecerá en los campos de la parte inferior de la página. Si no hay ninguna entrada resaltada, estos campos estarán en blanco y se puede agregar una nueva entrada rellenando el siguiente formulario:
Origen
POS
Destino
Prioridad
Comentarios
Haga clic en Agregar (o Editar en el caso de la modificación de una entrada existente)
Cuando una entrada se agrega correctamente, su estado se muestra como Codificación correcta. En caso contrario, póngase en contacto con el administrador. Al añadir una nueva entrada, también se calculará y mostrará su confianza
Al determinar el POS, utilice el lema de la entrada a menos que se refiera a una expresión o regla. De forma predeterminada, la asignación de un PDV se realiza automáticamente. Si la entrada es un sustantivo correcto que no debe traducirse, marque la casilla No traducir. Pase el ratón sobre el icono de información situado en la parte inferior derecha de la página para aprender a utilizar los métodos abreviados de teclado.
Descargando diccionarios
Haga clic en Descargar
Cambie el nombre del archivo descargado con la extensión “.txt” para abrir el archivo
Codificación de diccionario
Caracteres especiales
no se puede usar el hash #
es necesario proteger algunos caracteres:
las comillas «»»y los paréntesis «()» deben ir precedidos de una barra diagonal inversa «"para que se consideren parte de la entrada, no de la sintaxis de codificación; se mostrarán en la entrada codificada (sin la barra diagonal inversa)
barra diagonal inversa «"debe introducirse como «\\"“; se mostrará como «\»en la entrada codificada
tenga en cuenta que la mayoría de los guiones (en guión “-“, guión largo “—“etc.) se normalizarán a guión-menos “-” en la entrada de traducción (por lo que si la entrada del diccionario contiene un guión corto no coincidirá con la entrada normalizada)
la mayoría de las comillas se normalizarán a comillas rectas en la entrada de traducción, y las comillas rectas se pueden normalizar a otras comillas (locales) en la salida
Pistas de codificación
comillas «se puede utilizar para inmovilizar (parte de) la entrada para que no se inflexione; las comillas no se mostrarán en la entrada codificada
se pueden utilizar pistas de codificación entre paréntesis para el número (sg, pl), el género (m,f,neuter) y otra información morfo-sintáctica para ciertos idiomas
Normalizaciones
Los diccionarios de normalización (NDs) proporcionan una forma de regular el texto antes y después de la traducción, sirviendo como un medio para estandarizar la terminología y expandir las abreviaturas y acrónimos. Las ND también se pueden utilizar para estandarizar la ortografía y establecer una terminología común (por ejemplo, casos en los que se utilizan dos o más palabras para el mismo concepto).
Puede agregar los diccionarios de normalización (para el idioma de origen o para el idioma de destino) a un perfil. En caso de que se indique un diccionario de normalización para el idioma de origen, procesará el texto de entrada de origen antes de la traducción. Si el diccionario de normalización es para el idioma de destino, procesará el texto traducido.
Para crear un nuevo diccionario de normalización, en Resources, haga clic en Normalizations y, a continuación, en Create para abrir un cuadro de diálogo:
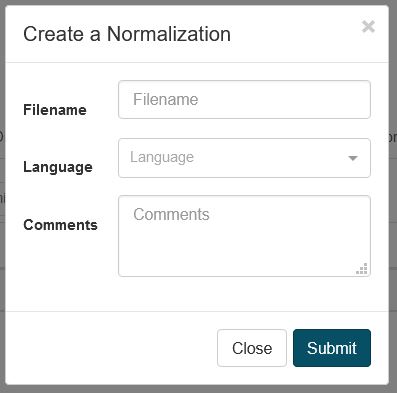
Elija un nombre para el diccionario de normalización y seleccione el idioma
Haga clic en Enviar para crear el diccionario de normalización
Se aplican las mismas directrices para cargar, descargar y editar un diccionario de normalización que para un diccionario del usuario. Consulte la sección anterior sobre Diccionarios.
Al importar un nuevo diccionario de normalización, asegúrese de que el encabezado tiene el formato correcto. El siguiente archivo de texto de ejemplo tiene formato para importar un diccionario de normalización a SYSTRAN Translate. Observe que <TAB> indica el carácter de tabulación.
#AUTHOR=SYSTRAN
#EMAIL=[email protected]
#SUMMARY=EN NORMALIZATION DICTIONARY
#ENCODING=UTF-8
#COVERED DOMAINS=coll
#GENERAL DICTIONARY DOMAINS=coll
#NORM
#EN EN_NO UPOS DOMAINS NOTE
youre <TAB> you are <TAB> sequence
4ever <TAB> forever <TAB> sequence
Una vez creado o importado un diccionario de normalización, puede asociarlo a un perfil.
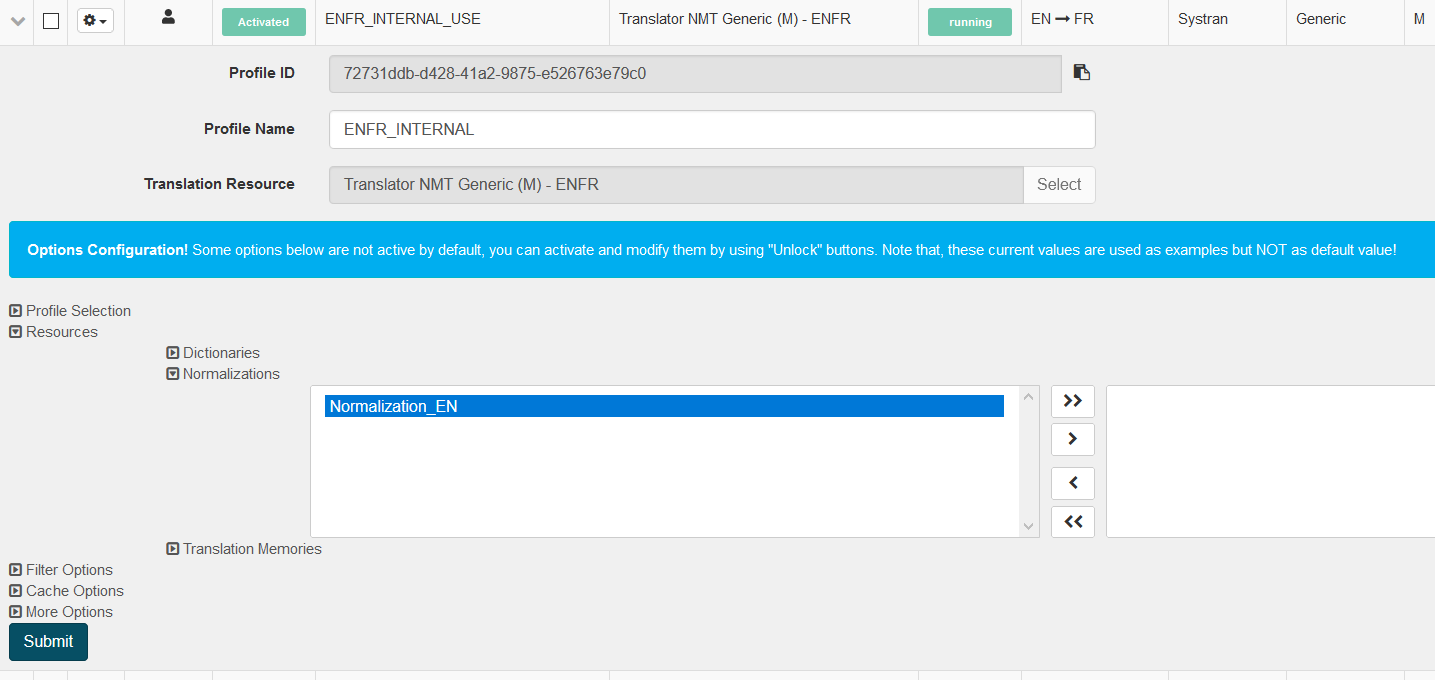
Memorias de traducción
Las memorias de traducción (TM) son útiles para establecer la coherencia de la traducción en una serie de archivos documentados. Las memorias de traducción son colecciones de pares de frases, cada una de las cuales incluye una frase de origen y su traducción, almacenadas en una base de datos bilingüe o multilingüe. El uso de una memoria de traducción permite recuperar palabras o expresiones de textos traducidos previamente durante el proceso de traducción. A diferencia de las entradas del diccionario del usuario, que siguen siendo susceptibles de análisis lingüístico, las traducciones de frases que existen en las memorias de traducción son estáticas. Cuando se traduce un documento con un perfil que contiene memorias de traducción, las oraciones presentes en la memoria (coincidencias exactas) anularán la traducción automática. En lugar de volver a traducir esa frase, SYSTRAN simplemente coloca en el documento la frase objetivo correlativa ya traducida.
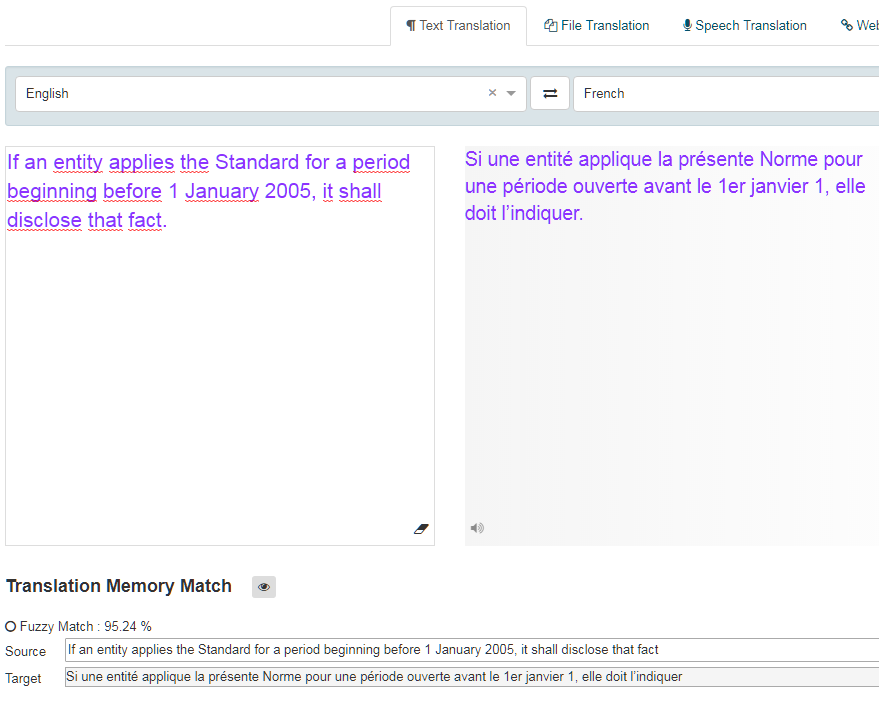
Al traducir con una memoria de traducción, un segmento del texto de origen que corresponde exactamente a un segmento de la base de datos de memoria de traducción es una coincidencia exacta con una puntuación de 1,0 (100%) y un segmento que corresponde parcialmente es una coincidencia parcial con un valor inferior a 1 (<100%). La puntuación compara la entrada con la coincidencia de memoria de traducción y calcula las similitudes entre las dos. Cuanto mayor sea el puntaje, más cerca estará el partido. La base de datos devolverá cualquier coincidencia superior al umbral de coincidencia parcial configurado por el administrador (70% de forma predeterminada). Estas coincidencias se mostrarán como Alternativas de coincidencia aproximada en la herramienta Traducción de texto y en el Editor de traducción al revisar una traducción de archivo.
En el cuadro Traducción de texto, la coincidencia parcial se resaltará en verde y se mostrará la puntuación.
Además, las memorias de traducción pueden utilizarse como corpus de pruebas, ajustes o formación en sus proyectos de formación en traducción.
Creación de memoria de traducción
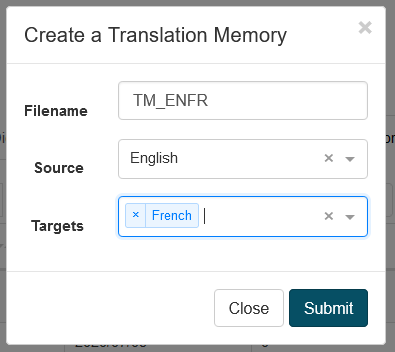
Crear memorias de traducción
Para crear una memoria de traducción, haga clic en el botón de creación y, a continuación, tendrá que archivar el nombre de archivo de la TM, un idioma de origen y un idioma de destino.
Carga de una memoria de traducción
Los archivos de intercambio de memoria de traducción (TMX) son una especificación de XML. SYSTRAN Translate soporta versiones TMX entre 1.2 y 1.4. Para obtener más información, consulte la página TMX de la Asociación de Normas del Sector de la Localización (https://www.gala-global.org/lisa-oscar-standards/).
Para cargar una memoria de traducción, haga clic en Recursos, a continuación en Memoria de traducción, seleccione la memoria de traducción deseada y haga clic en “Editar”. Haga clic en «Anexar» Aparecerá un cuadro de diálogo:
Una vez cargadas, las entradas de la memoria de traducción aparecerán en la página Memoria de traducción.
Nota
Se recomienda cargar TM que no supere los 200000 segmentos.
Para utilizar una memoria de traducción con un perfil:
Haga clic en Perfiles
Seleccione los perfiles
Expandir las opciones de perfiles
En Recursos, seleccione la memoria de traducción deseada
Haga clic en Enviar
Editor de memorias de traducción
Ir a Recursos > Memorias de traducción
Pulse Editar
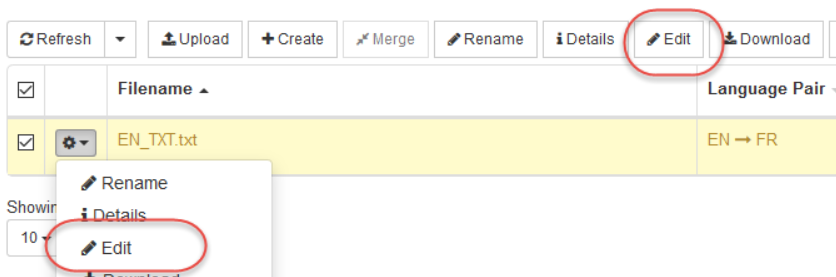
Se abrirá el Editor de memoria de traducción
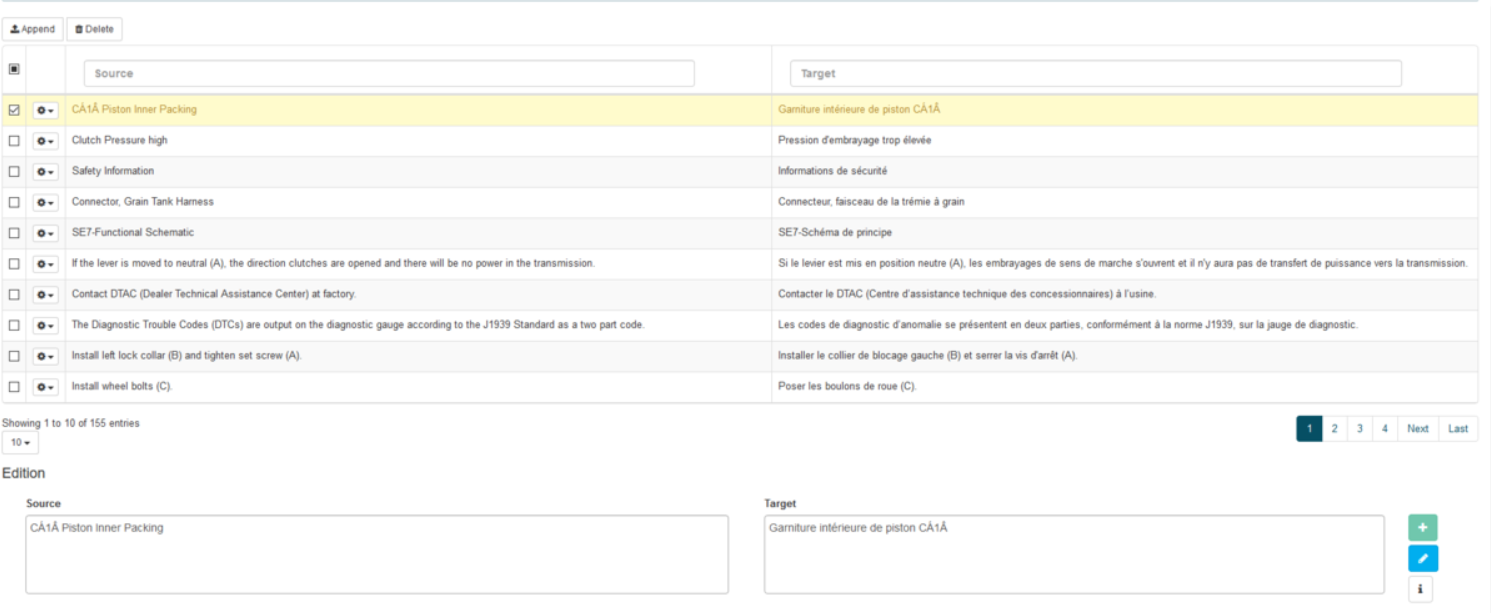
Editar una frase
Seleccione la entrada
Actualizar los campos necesarios (origen y/o destino)
Haga clic en el botón “Editar” o pulse la tecla Enter en el teclado
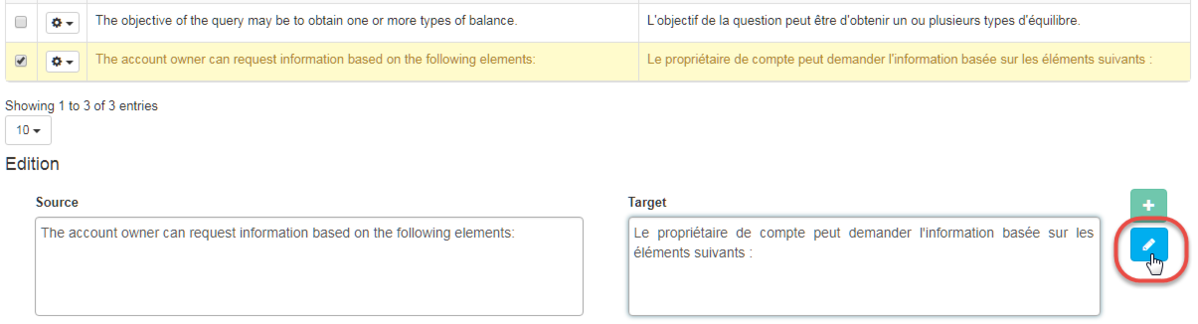
Añadir un nuevo segmento en la memoria de traducción
Puede agregar directamente una entrada a través de los campos de origen y destino:


Buscar una frase
Para buscar oraciones específicas, introduzca la palabra o frase que está buscando en el campo Segmento de origen o de destino:
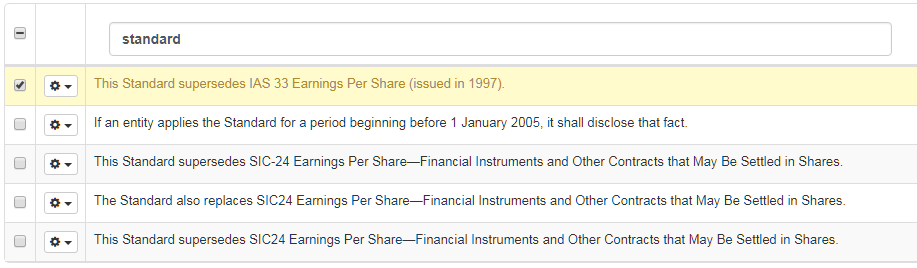
Suprimir un segmento
Seleccionar un segmento
Haga clic en Eliminar
Haga clic en Enviar para confirmar la eliminación